Projects
Jump to: Current projects | Completed projectsCurrent projects

GraphNEx
We are designing a graph-based framework for developing inherently explainable artificial intelligence.

CORSMAL
We explore the fusion of multiple sensing modalities (sound, vision, touch) to accurately and robustly estimate the physical properties of objects a person intends to hand over to a robot.

Auditory drones
We are equipping drones with the ability to hear, despite the strong ego-noise they generate, through single-channel data-driven models and multi-channel signal processing approaches.
Privacy preserving machine learning
We train neural networks by promoting the extraction of features that make it difficult for an adversary to accurately predict private attributes.
Multi-modal machine learning
We explore multi-modal training strategies with cross-modal knowledge transfer to improve the expressiveness of a modality at test time.
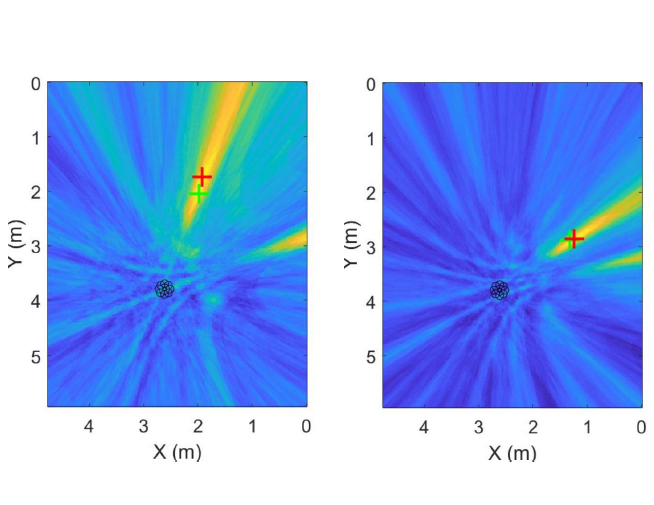
Audio-visual sensing
We are interested in enabling autonomous systems to interact with people through acoustic and visual sensing. We develop algorithms for localisation, tracking, speech enhancement and event detection.

Underwater vision and vision through haze
We are developing image dehazing approaches for colour correction in underwater scenes. We are also using the by-product of the dehazing process to infer 3D scene information.

AUTONOMY
We are designing solutions for cellular-connected Unmanned Aerial Vehicles systems with 3D high mobility to accomplish complex tasks with limited human supervision.
Completed projects

Self-flying camera networks
We develop distributed vision-based control algorithms for multi-rotor robotic platforms equipped with cameras. One of our goals is to autonomously film moving targets from multiple viewpoints in 3D.

Action recognition from body cameras
We are interested in extracting robust features from first-person videos to classify the actions of people wearing a camera, without using inertial sensors.
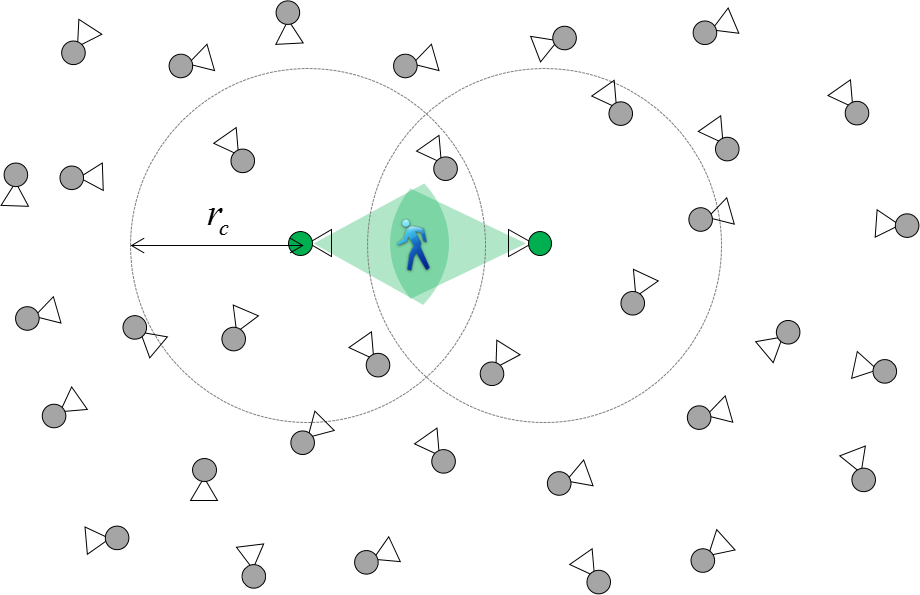
Collaborative sensing
We designed scalable and robust methods for moving cameras (and microphones) to interact locally in coalitions in order to make coordinated decisions under resource and physical constraints.
WiSE-MNet: a smart-camera network simulator
We developed a flexible and extensible simulation environment that enables high-level abstractions for sensing, processing and wireless communications for distributed vision and multimedia applications.

MUTAVIT: Multi-target video tracking
We designed tracking algorithms to estimate the trajectories of multiple objects, both on-line and off-line. We also developed evaluation measures and interactive visualisation tools to help improve performance.

Self-XT: Self-evaluating and self-correcting trackers
We defined mechanisms to enable visual trackers to avoid drifting or to recover from failures. These self-correction capabilities are based on self-evaluation and cross-evaluation algorithms.

Automated editing of user-generated videos
We devised audiovisual analysis and processing techniques to automate the localisation, synchronisation and editing of multi-view user-generated videos.

FAREC: Facial Affect Recognition
We developed methods to recognise facial expressions from 3D scans and subtle facial expression from videos. In particular, we looked at the problems of scan and frame registration, feature extraction and representation.

Privacy and smart cameras
Video cameras coupled with local processing units are becoming faster, smaller and smarter. We looked at how cameras themselves can help preserve the privacy of individuals.
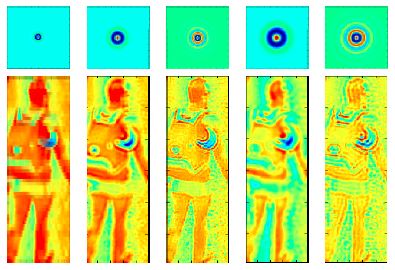
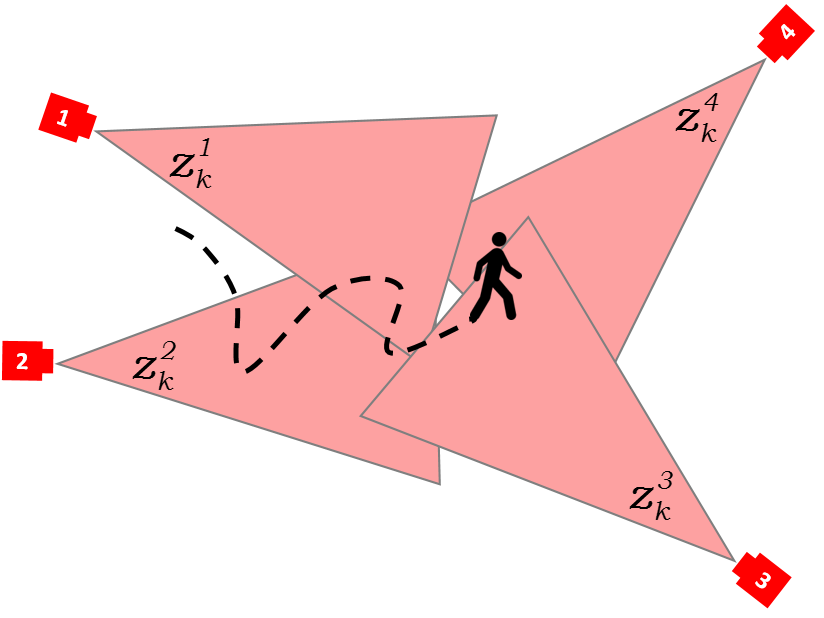
PRE-ID: multi-camera person re-identification in crowd
We developed algorithms to recognize a person when viewed by cameras at different locations using their appearance and potential paths they can choose to follow.

Self-localisation of CCTV cameras
We defined models and algorithms that use trajectory of moving objects to iteratively calibrate (i.e. to localize) a network of cameras with disjoint fields of view.
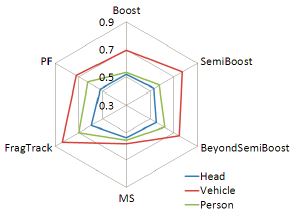
PFT: protocols for evaluating video trackers
We defined a set of performance measures and a protocol for the validation and comparison of video trackers. See here to download the measures, the dataset and the ground truth.
ABEDE: Abnormal event detection
We designed an abnormal visual event detection approach that uses a non-linear subspace and graph-based manifold learning to model local motion patterns with a supervised novelty classifier.
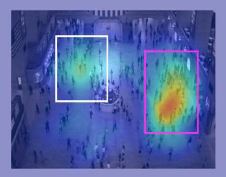
RECINT: Recognizing Interactions
We developed methods that recognize human interactions in observable areas and predict them in unobservable areas.

FADAR-3D: 3D face detection, analysis and recognition
We defined an accurate framework for detecting and segmenting faces, localizing landmarks and achieving fine registration of face meshes based on the fitting of a facial model. See here.
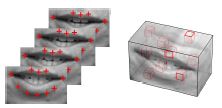
AUVIS: Audio-visual speech recognition
We developed an audio-visual fusion techniques to recognise speech (e.g. spoken digits) captured in video with poor sound. The technique performs significantly better than utilising either audio or video alone.

Perceptual enhancements for image and video coding
We develped selective blurring algorithms that mimic the optical distance blur effects that occur naturally in cameras.

Smart Camera
We developed algorithms that extend the capabilities of standard cameras by generating a scalable content description for textual scene description, video surveillance and augmented reality.

CASHD: Cast shadow detection
The shape and the colour of segmented objects may be modified by the presence of shadows. To provide a correct description of objects we developed a shadow recognition technique for videos and images.
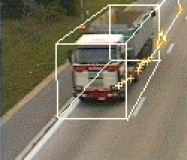
MOTINAS: Multi-modal object tracking in a network of audio-visual sensors
We developed algorithms for multi-modal and multi-sensor tracking using STAC sensors (stereo microphones coupled with cameras) and created a test corpus and its associated ground-truth data.

art.live: Authoring tools for live mixed reality
We developed an innovative authoring tool that enables artists/users to easily create mixed real and virtual narrative spaces and disseminate them in real-time to the public.
Multimedia object descriptors extraction from video
We developed a framework for high-level semantic scene interpretation based on the segmentation, tracking and indexing of moving objects in video using intelligent agents.

Analysis of video sequences to track moving objects
We developed algorithms for identifying, indexing and tracking moving objects and recognizing automatically changes of interest in a given scene.