Algorithms and Data Structures in an Object-Oriented Framework (“ADSOOF”)
Implementing ArrayLists using Linked Lists
When we considered implementing Lisp lists, we first considered an implementation using arrays, then considered an implementation using linked lists. The linked list implementation turned out to be more efficient, saving space because it made use of shared cells, and saving time because it did not involve whole arrays being copied. Part of the reason the linked list implementation turned out to be more efficient is that there is a close correspondence between Lisp lists and linked lists.
We have seen previously that arrayLists may be implemented using arrays. They may also be implemented with linked lists. The array implementation is generally the most efficient since there is a close correspondence between arrays and arrayLists. However, it gives us chance for more practice with the linked list data structure if we consider how it may be used to implement an arrayList abstract data type.
Like our implementation of Lisp lists with linked lists, our implementation
of arrayLists will have a single private variable in an object
which is set to refer to a linked list structure. It will be made
up of the same sort of Cell objects as we used with
for Lisp lists, with a nested class to define them. However,
as arrayLists are a destructive or mutable type of object, the operations
on it work by changing the linked list structure referred to inside
the object, rather than constructing a new one and putting it inside a
new object. If we call the new type MyArrayList5, it
will have the following structure:
class MyArrayList5 <E>
{
private Cell<E> myList;
public MyArrayList5()
{
myList=null;
}
...
private static class Cell <T>
{
T first;
Cell<T> next;
Cell(T h,Cell<T> t)
{
first=h;
next=t;
}
}
}
The recursive variable in the nested class is called next
here rather than rest (which is what we used when we had otherwise
the same class for implementing Lisp lists) as that better captures the idea
that it represents a link in the linked list, but changing the name of
the variable does not change the way the class operates. This time
there is a public constructor which is the equivalent of the zero-argument
constructor in Java's ArrayList class provided in the
java.util package, it returns an object representing
an empty arrayList. The data structure representing the empty arrayList
is just null. The class has a type variable E
allowing it be used to build arrayLists of any element type.
Following this, we need methods representing the basic operations
on an arrayList. These will change the linked list data structure.
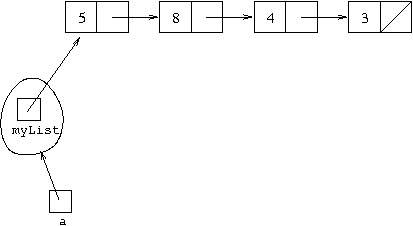
Let us consider an example. Suppose we want the arrayList object
representing the arrayList we can represent textually as
[5,8,3,4]. We can use the same representation we used
for the linked list [5,8,3,4], so if a is
the name of the object referring to it, diagrammatically this can be
shown as:
Now suppose we want to represent the effect of calling a.add(7).
This needs to change the structure to:
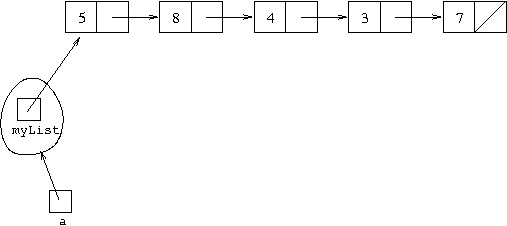
Unlike cons with Lisp lists, the new item is added at
the back rather than the front of the list.
To achieve this, what we need is a variable which is an alias to the
last cell (that is the cell whose next variable is
null). The reason we need to add the new cell through an alias
to an existing cell in the linked list is that this causes the new cell
to be linked into the linked list. If the alias variable is called
ptr, then executing
ptr.next = new Cell(n,null)
will add a new cell to the end of the list whose first
variable is set to the value in n (let us assume that is 7)
and whose next variable is set to null.
So we need to reach the following situation:
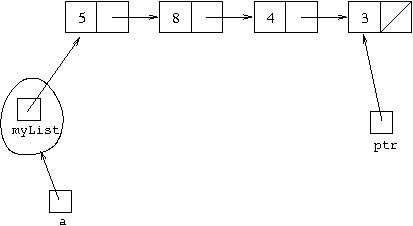
To reach this situation, we start with ptr at the front
of the list:
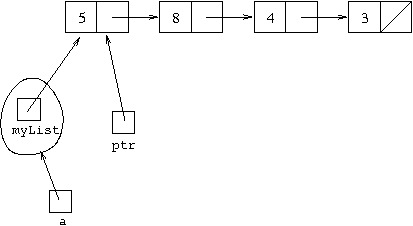
which is achieved by executing ptr=myList. Then executing
ptr=ptr.next will cause ptr to stop referring
to what it is referring to and start referring to what ptr.next
refers to, that is, to the next cell in the linked list:
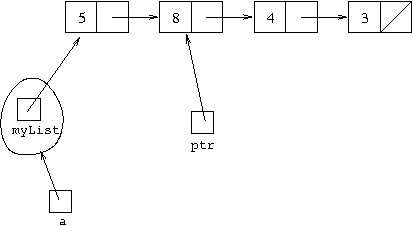
Each time we execute ptr=ptr.next we “move” ptr
one link down the linked list. If we continue doing this until ptr
refers to a cell whose next variable is set to null,
we will move it to the last cell. This leads to the following code for
add:
public void add(E item)
{
if(myList==null)
myList = new Cell<E>(item,null);
else
{
Cell<E> ptr=myList;
for(; ptr.next!=null; ptr=ptr.next) {}
ptr.next = new Cell<E>(item,null);
}
}
Note that special code is needed for the case where myList
is equal to null, that is adding an item to an empty
arrayList.
It is because the variables first and next
are not declared as private in the class Cell
that they can have their values changed directly by code in the class
MyArrayList5. However, no code outside MyArrayList5
can change their values directly because the variable myList
which refers to the linked list structure is declared as private.
In fact since the type Cell is declared as private,
it isn't even possible to have variables of that type outside the class
MyArrayList5.
The variable ptr is referred to as a “pointer” because
we think of it as something that can be made to point to various
cells in the structure. The technique of running a pointer down a linked
list using a loop with update ptr=ptr.next is common for
operations on linked list. We can see it also in the code which implements
the size operation:
public int size()
{
int count=0;
for(Cell <E> ptr=myList; ptr!=null; ptr=ptr.next, count++) {}
return count;
}
Here, each time the pointer is moved one link down, a count is increased
by one. As a consequence, when the pointer has gone right through the
list, the count will give the total number of items in the list. Note
the difference between the loop condition uses previously
ptr.next!=null and the loop condition used now,
ptr!=null. In the first case, as soon as the pointer
reached the last cell, execution exits the loop. In the second case,
the loop is obeyed one more time with the pointer pointing to the last cell.
So in the first case when the loop exits the pointer is left pointing to
the last cell in the linked list, while in the second case it is left set
to null. In our code for size the pointer
ptr is declared inside the for loop, which means it
can't be used outside it. In our code for add however,
we need to use ptr after the loop has finished, so it is
declared before the loop.
Now we need code for the get and set operations,
which are the direct equivalent of using array indexing. In this case
we need a loop which ends with ptr pointing to the
posth cell in the linked list. So we have the same pattern
of ptr running down the linked list, with a count kept
of the number of links gone over. When this count is equal to pos
the pointer points to the posth cell. If ptr
becomes equal to null before the count becomes equal to
pos it indicates there aren't enough cells in the linked list,
so an IndexOutOfBoundsException is thrown. When ptr
points to the posth cell, executing return ptr.first
returns the data item in that cell, while executing ptr.first=item
causes it to be changed to refer to the object referred to by item.
So this gives the following code:
public E get(int pos)
{
Cell<E> ptr=myList;
for(int count=0; count<pos&&ptr!=null; ptr=ptr.next, count++) {}
if(ptr==null)
throw new IndexOutOfBoundsException();
return ptr.first;
}
public void set(int pos,E item)
{
Cell<E> ptr=myList;
for(int count=0; count<pos&&ptr!=null; ptr=ptr.next, count++) {}
if(ptr==null)
throw new IndexOutOfBoundsException();
ptr.first=item;
}
You can see that the code for the method set causes the
value of the first variable to be changed in the
Cell object that ptr refers to. The
Cell object itelf remains the same object. This is
a destructive change that could cause problems if the Cell
object was shared by other linked list, since they would also get
this change made to them. However, we know this can't
happen as it can be referenced only through the myList
variable of the MyArrayList5 object which the
set method is called on.
The disadvantage of this representation can be seen by the way these operations have to go through the cells in the list to reach a cell indexed by a particular value. In terms of the big-O notation, this is O(N). When using an array as representation, accessing an array component indexed by a particular value is done in one step, with no dependency on the size of the array, so it is O(1).
ArrayLists have an operation add which takes a
single argument and adds it to the end of the existing contents
of the arrayList. They also have an operation add which
takes two arguments, the first an integer, and adds the item given by the
second argument to the list of items in the arrayList at the position
given by the integer argument. This is not the same as set,
for which we gave code above, as that changes the value of the
item indexed by the integer. With add nothing is changed,
instead all following items are moved up one place.
Adding a new cell into a linked list can be done through a pointer
to the previous cell. If ptr points to a cell in
a linked list, then executing
ptr.next = new Cell(item,ptr.next)
will cause ptr.next to refer to a new Cell
object whose first variable is set to item and
whose next variable is set to what ptr.next
used to refer to. So if the situation is:
and item holds 7, the result
of executing ptr.next = new Cell(item,ptr.next)
will be:
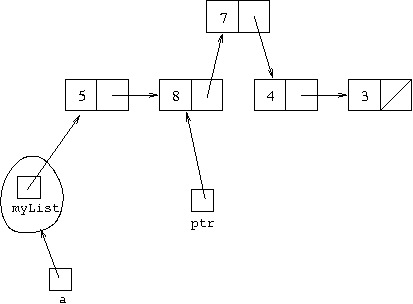
Executing ptr.next = ptr.next.next causes
ptr.next to start referring to what the next
variable of the cell it originally referred to refers to. From the above
original position, that would lead to:
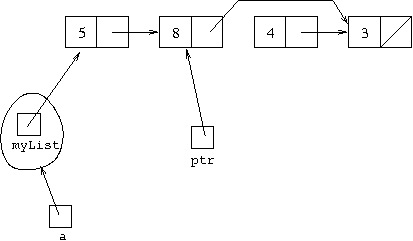
But since an object disappears once nothing refers to it, that can be considered as:
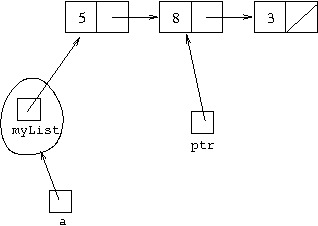
So this serves to cut the cell after the cell that ptr is
referring to out from the list.
In both cases here, since cells are added into and taken out of the list, the following cells automatically change their position in the list, so there is no need to move them up or down as there was in the array implementation. So a linked list implementation may be preferred if the main operations that are to be done on it are to add and remove items from particular positions, rather than just to access or change items at particular positions.
The techniques described here lead to the code for these operations:
public void add(int pos,E item)
{
if(pos==0)
myList = new Cell<E>(item,myList);
else
{
Cell<E> ptr=myList;
for(int count=1; ptr!=null&&count<pos; ptr=ptr.next,count++) {}
if(ptr==null)
throw new IndexOutOfBoundsException();
ptr.next = new Cell<E>(item,ptr.next);
}
}
public E remove(int pos)
{
E item;
if(myList==null)
throw new IndexOutOfBoundsException();
else if(pos==0)
{
item=myList.first;
myList=myList.next;
return item;
}
else
{
Cell<E> ptr=myList;
for(int count=1; ptr.next!=null&&count<pos; ptr=ptr.next,count++) {}
if(ptr.next==null)
throw new IndexOutOfBoundsException();
item=ptr.next.first;
ptr.next=ptr.next.next;
return item;
}
}
Separate code is needed to deal with the case where the item being added
or deleted is the first item in the list. There also needs to be
code to exit from the loop moving the pointer down and throw
a IndexOutOfBoundsException if the pointer reaches the
end of the linked list before the count of its position reaches the
required value. The method remove has as its return value
a reference to the item that was removed, so this needs to be saved
in a local variable called item before the cell
containing it is cut out from the list.
The other remove operation takes as its
argument the item to be removed and causes it to be removed from the
collection. It returns a boolean value, false
if the item does not appear in the collection and so cannot be removed,
true otherwise. Again, the technique that has to be
used is to get a pointer, ptr, to point to the cell before
the one that is to be removed and then execute
ptr.next = ptr.next.next. The test that the
next cell to the one pointed to by ptr contains an item
equal to that referenced by the variable item is
item.equals(ptr.next.first). Before testing this we have
to test that ptr.next is not equal to null,
so we know there is a next cell to test. This leads to the following code:
public boolean remove(E item)
{
if(myList==null)
return false;
else if(item.equals(myList.first))
{
myList=myList.next;
return true;
}
else
{
Cell<E> ptr=myList;
for(; ptr.next!=null&&!item.equals(ptr.next.first); ptr=ptr.next) {}
if(ptr.next==null)
return false;
else
{
ptr.next = ptr.next.next;
return true;
}
}
}
equals method
Any object can have the method equals called on it with
another object as the argument. We used equals in the above
code for remove with an argument not of type int.
If a class does not have its own equals method, it will use
the default one, which is that obj1.equals(obj2) only
returns true when obj1 and obj2
are aliases of the same object. This may not be the behaviour
we require. For example, in the situation illustrated diagrammatically
below:
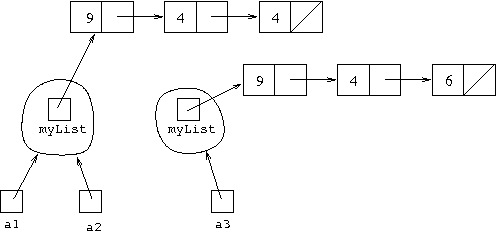
the default implementation of equals would mean that a1.equals(a2)
will evaluate to true, but a1.equals(a3) will evaluate to false.
If we want equals to return true in
situations other than aliasing, we need to write our own
equals method in classes where objects are going
to be tested using equals. For example, we could have an
arrayList of Lisp lists of integers. This type would be written
ArrayList<LispList<Integer>>. Suppose
a refers to an arrayList of this type, and ls
refers to a list object representing [9,4,6]. We would
want a.remove(ls) to change the arrayList referred to by
a so that if a list [9,4,6] is in it, it
will be removed, even if it is not an alias of ls.
In order to achieve this, it would be necessary to add the following
method to the class LispList:
public boolean equals(Object other)
{
if(!(other instanceof LispList))
return false;
LispList<E> otherList = (LispList) other;
if(this.isEmpty())
return otherList.isEmpty();
else if(otherList.isEmpty())
return false;
else
return this.head().equals(otherList.head()) &&
this.tail().equals(otherList.tail());
}
Note that due to Java's definition of equals, the
parameter has to be of type Object and then cast to
type LispList<E>. This is to enable it to override the equals
method in class Object. If the argument passed to the
equals method is not of the same type the method is called on,
the method call should return false, a check for this is
done with the instanceof test. If this check wasn't there,
a ClassCastException would be thrown, but the recommendation
is that equals should return false when trying to test
two objects of different types rather than throw an exception.
Note also that because type variables are a compile time feature of
Java but not a run time feature, they cannot be used in sinstanceof
tests or in type casting.
The rest of the code for the equals method should be fairly
intuitive: two lists are equal either if they are both empty, or if their heads
are equal and their tails are equal. This intuitive definition
translates directly to a recursive method. If you prefer to think
iteratively, however, the following would work just as well:
public boolean equals(Object other)
{
if(!(other instanceof LispList))
return false;
LispList<E> list1 = this;
LispList<E> list2 = (LispList) other;
while(!list1.isEmpty()&&!list2.isEmpty()&&list1.head().equals(list2.head()))
{
list1 = list1.tail();
list2 = list2.tail();
}
return list1.isEmpty()&&list2.isEmpty();
}
The variables list1 and list2 are
initially set to the two lists and then repeatedly set to their
tails until either one is empty, or their heads are not equal.
If this process ends because one is empty and the other is not, or
because the two lists do not have equal heads, the initial two lists
were not equal. If when it ends because the first list is empty, the
second is two it must be that all the previous matching head items were
equal, and the lengths must be the same, so the initial two lists must be
equal.
However, a more efficient version of equals for Lisp lists
would note that as the code is inside the class LispList,
we can program it directly in terms of the linked list data structure
inside this class, rather than in terms of the public operations of
the LispList class. Doing it this way gives the code:
public boolean equals(Object other)
{
if(!(other instanceof LispList))
return false;
LispList<E> that = (LispList) other;
Cell<E> ptr1 = this.myList;
Cell<E> ptr2 = that.myList;
for(;ptr1!=null&&ptr2!=null; ptr1=ptr1.rest,ptr2=ptr2.rest)
if(!ptr1.first.equals(ptr2.first))
return false;
return (ptr1==null&&ptr2==null);
}
This shows the feature we saw
previously
of a method accessing the private variables of another object of the same class
as the one the method was called on. In the above code, this.myList means the
private variable myList of the LispList<E>
object which the method call to equals was made on, and that.myList
means the private variable myList of the LispList<E>
object which was passed to the method call as its argument. If the name of a variable declared
as a field in a class is used on its own in a non-static method in the class, it is taken to
be the variable of that name inside the object the method is called on. So in the above
code where it is written this.myList, it could have been written as just
myList. However, writing it in this way including the word this,
which in Java means “the object this method call is made on”, emphasises the way we are
comparing two different linked lists.
The above implementation of equals can be improved on because it doesn't take
account of the fact that our implementation of Lisp lists using linked lists could result in
cells in the linked list being shared.
So the two different linked lists this.myList and that.myList
may not be completely different, they may share cells.
If we have ptr1 and ptr2 running down two
linked lists and they reach the case where both point to the same cell,
we don't have to carry on checking that the data in the cells they point
to is equal because from then on they will always point to the same cell
as both are moved down. So if ptr1 and ptr2
point to the same cell, we know then that the two linked lists being tested
must be equal without having to go any further. The test that two variables
refer to the same object is ==, so this gives us the following
improved code for equals:
public boolean equals(Object other)
{
if(!(other instanceof LispList))
return false;
Cell<E> ptr1 = this.myList;
Cell<E> ptr2 = ((LispList) other).myList;
for(;ptr1!=ptr2&&ptr1!=null&&ptr2!=null; ptr1=ptr1.rest,ptr2=ptr2.rest)
if(!ptr1.first.equals(ptr2.first))
return false;
return (ptr1==ptr2);
}
Note that a disadvantage of writing methods for extra operations in a
way which uses the internal data structure is that if the internal
data structure changes, the methods have to be changed. This last
version of equals for Lisp lists would have to be
completely rewritten if we changed to an array-and-count representation
for Lisp lists, whereas the previous code could be used unchanged since
nothing in it relies on knowing the internal data structure of a
LispList object.
Java's own code for ArrayList as provided in its library
implements remove and other operations by using the
equals method found in the element type, so remembering to
provide code for an equals is necessary for any class of
objects you intend to put in arrayLists if you intend to use methods
like remove on them.
The methods indexOf and lastIndexOf also rely
on the use of the equals method. Here is code for them
for the class with arrayLists implemented by linked lists:
public int indexOf(E item)
{
int count=0;
Cell<E> ptr=myList;
for(; ptr!=null&&!item.equals(ptr.first); ptr=ptr.next, count++) {}
if(ptr==null)
return -1;
else
return count;
}
public int lastIndexOf(E item)
{
int pos=-1;
Cell<E> ptr=myList;
for(int count=0; ptr!=null; ptr=ptr.next, count++)
if(item.equals(ptr.first))
pos=count;
return pos;
}
Both involve running a pointer down the linked list and keeping a
count of the number of links moved down. In the case of
indexOf, the loop terminates when an item equal to the
item whose position is being searched for is found, and the count of
the number of links moved down is returned as its position. If it terminates
with the pointer equal to null, that indicates it has
gone right through the linked list and not found the item,
so -1 is returned. In the case of lastIndexOf,
the pointer must move down the whole list. If it finds an item equal to
the one being searched for, a variable keeping the highest position so
far of such an item is updated to the new position.
You can find the complete code for MyArrayList5 in
the code folder
in the file MyArrayList5.java.
Also in that directory is a file
UseMyArrayLists5.java
which can be used to test the class MyArrayList5.
In the file UseArrayListsLispLists.java
you will find code which prompts you to type a list of list of integers
(for example [[2,3,8],[1,12,9,7],[20,6,4],[3,7]]) which
is stored in an arrayList of Lisp lists of integers. It then asks you
to type in a single list, for example [20,6,4], and it
will give you the position of that list in the arrayList. In this case,
you would expect it to give 2. You will find, however,
that unless you have added the method equals, given
above, to the class
LispList it will tell you that the list is not found
in any position. This indicates how Java's ArrayList
relies on equals being implemented in the class of components
of an arrayList. Note that the code in UseArrayListsLispLists.java
uses an aspect of Java's library we have not covered (“regular expressions”)
in order to divide a string up to make the list of lists.
Last modified: 5 July 2019