Speech separation and extraction by combining superdirective beamforming and blind source separation
Abstract
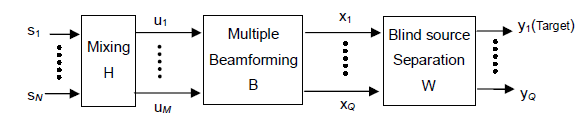
Emulating human auditory systems, a two-stage target speech extraction method is proposed which combines fixed beamforming and blind source separation. With the target speaker remaining in the vicinity of a fixed location, several beams from a microphone array point at an area containing the target, then the beamformed output is fed to a blind source separation scheme to get the target signal. The fixed beamforming preprocessing enhances the robustness to time-varying environments and makes the target signal dominant in the beamformed output and hence easier to extract.
Reference
- L. Wang, H. Ding, and F. Yin (2011): Target speech extraction in cocktail party by combining beamforming and blind source separation. Acoustics Australia, 39(2): 64-68.
- L. Wang, H. Ding, and F. Yin (2011): A region-growing permutation alignment approach in frequency-domain blind source separation of speech mixtures. IEEE Transactions on Audio, Speech, and Language Processing 19(3): 549-557.
A. Acoustic scenario
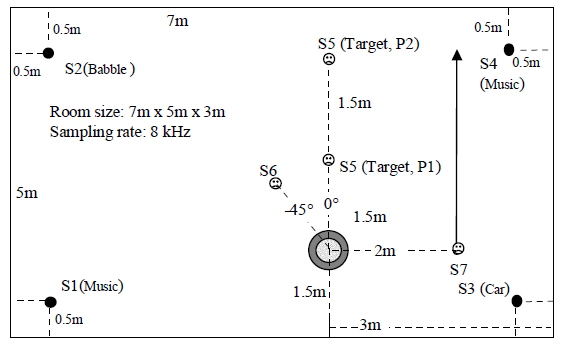
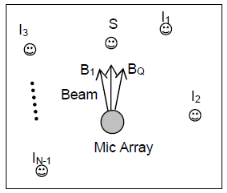
B. Signal flow of the combined method
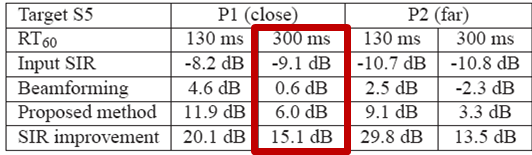
C. Experiment results
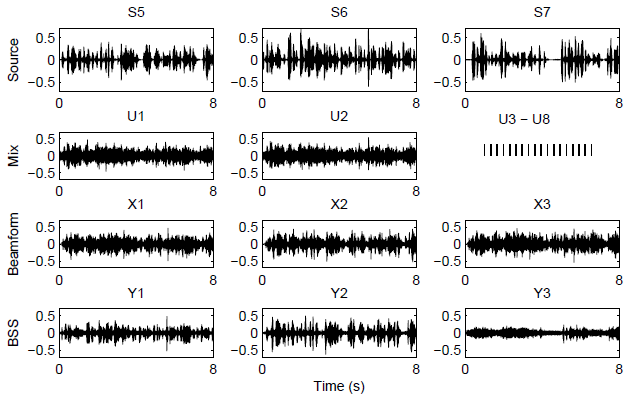
Audio files (according to the waveform figure)
| Source | S5 | S6 | S7 |
| Mix | U1 | U2 | U3-U8 |
|---|---|---|---|
| Beamforming | X1 | X2 | X3 |
| BSS | Y1 | Y2 | Y3 |
Last modification: | Created: 13/02/2015