Recording problems (incident count metrics)No serious attempt to use measurement for software QA would be complete without rigorous means of recording the various problems that arise during development, testing, and operation. No software developer consistently produces perfect software the first time. Thus, it is important for developers to measure those aspects of software quality that can be useful for determining
The terminology used to support this investigation and analysis must be precise, allowing us to understand the causes as well as the effects of quality assessment and improvement efforts. In this section we describe a rigorous framework for measuring problems The problem with problems In general, we talk about problems, but Figure 6.1 depicts some of the components of a problem’s cause and symptoms, expressed in terms consistent with IEEE standard 729. [IEEE 729].
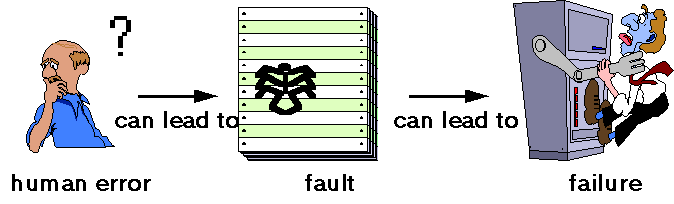
Figure 6.1: Software quality terminology A fault occurs when a human error results in a mistake in some software product. That is, the fault is the encoding of the human error. For example, a developer might misunderstand a user interface requirement, and therefore create a design that includes the misunderstanding. The design fault can also result in incorrect code, as well as incorrect instructions in the user manual. Thus, a single error can result in one or more faults, and a fault can reside in any of the products of development. On the other hand, a failure is the departure of a system from its required behavior. Failures can be discovered both before and after system delivery, as they can occur in testing as well as in operation. It is important to note that we are comparing actual system behavior with required behavior, rather than with specified behavior, because faults in the requirements documents can result in failures, too. During both test and operation, we observe the behavior of the system. When undesirable or unexpected behavior occurs, we report it as an incident, rather than as a failure, until we can determine its true relationship to required behavior. For example, some reported incidents may be due not to system design or coding faults but instead to hardware failure, operator error or some other cause consistent with requirements. For this reason, our approach to data collection deals with incidents, rather than failures. The reliability of a software system is defined in terms of incidents observed during operation, rather than in terms of faults; usually, we can infer little about reliability from fault information alone. Thus, the distinction between incidents and faults is very important. Systems containing many faults may be very reliable, because the conditions that trigger the faults may be very rare. Unfortunately, the relationship between faults and incidents is poorly understood; it is the subject of a great deal of software engineering research. One of the problems with problems is that the terminology is not uniform. If an organization measures its software quality in terms of faults per thousand lines of code, it may be impossible to compare the result with the competition if the meaning of "fault" is not the same. The software engineering literature is rife with differing meanings for the same terms. Below are just a few examples of how researchers and practitioners differ in their usage of terminology.
Until terminology is the same, it is important to define terms clearly, so that they are understood by all who must supply, collect, analyze and use the data. Often, differences of meaning are acceptable, as long as the data can be translated from one framework to another. We also need a good, clear way of describing what we do in reaction to problems. For example, if an investigation of an incident results in the detection of a fault, then we make a change to the product to remove it. A change can also be made if a fault is detected during a review or inspection process. In fact, one fault can result in multiple changes to one product (such as changing several sections of a piece of code) or multiple changes to multiple products (such as a change to requirements, design, code and test plans). We describe the observations of development, testing, system operation and maintenance problems in terms of incidents, faults and changes. Whenever a problem is observed, we want to record its key elements, so that we can then investigate causes and cures. In particular, we want to know the following:
The eight attributes of a problem have been chosen to be (as far as possible) mutually independent, so that proposed measurement of one does not affect measurement of another; this characteristic of the attributes is called orthogonality. Orthogonality can also refer to a classification scheme within a particular category. For example, cost can be recorded as one of several pre-defined categories, such as low (under $100,000), medium (between $100,000 and $500,000) and high (over $500,000). However, in practice, attempts to over-simplify the set of attributes sometimes result in non-orthogonal classifications. When this happens, the integrity of the data collection and metrics program can be undermined, because the observer does not know in which category to record a given piece of information.
On the surface, our eight-category report template should suffice for all types of problems. However, as we shall see, the questions are answered very differently, depending on whether you are interested in faults, incidents or changes. Incidents An incident report focuses on the external problems of the system: the installation, the chain of events leading up to the incident, the effect on the user or other systems, and the cost to the user as well as the developer. Thus, a typical incident report addresses each of the eight attributes in the following way.
There are two separate notions of mode. On the one hand, we refer to the types of symptoms observed. Ideally, this first aspect of mode should be a measures of what was observed as distinct from effect, which is a measure of the consequences. For example, the mode of an incident may record that the screen displayed a number that was one greater than the number entered by the operator; if the larger number resulted in an item’s being listed as "unavailable" in the inventory (even though one was still left), that symptom belongs in the "effect" category.
The second notion of mode relates to the conditions of use at the time of the incident. For example, this category may characterize what function the system was performing or how heavy the workload was when the incident occurred. Only some of the eight attributes can usually be recorded at the time the incident occurs. These are:
The others can be completed only after diagnosis, including root cause analysis. Thus, a data collection form for incidents should include at least these five categories. When an incident is closed, the precipitating fault in the product has usually been identified and recorded. However, sometimes there is no associated fault. Here, great care should be exercised when closing the incident report, so that readers of the report will understand the resolution of the problem. For example, an incident caused by user error might actually be due to a usability problem, requiring no immediate software fix (but perhaps changes to the user manual, or recommendations for enhancement or upgrade). Similarly, a hardware-related incident might reveal that the system is not resilient to hardware failure, but no specific software repair is needed. Sometimes, a problem is known but not yet fixed when another, similar incident occurs. It is tempting to include an incident category called "known software fault," but such classification is not recommended because it affects the orthogonality of the classification. In particular, it is difficult to establish the correct timing of an incident if one report reflects multiple, independent events; moreover, it is difficult to trace the sequence of events causing the incidents. However, it is perfectly acceptable to cross-reference the incidents, so the relationships among them are clear. The need for cross-references highlights the need for forms to be stored in a way that allows pointers from one form to another. A paper system may be acceptable, as long as a numbering scheme allows clear referencing. But the storage system must also be easily changed. For example, an incident may initially be thought to have one fault as its cause, but subsequent analysis reveals otherwise. In this case, the incident’s "type" may require change, as well as the cross-reference to other incidents. The form storage scheme must also permit searching and organizing. For example, we may need to determine the first incident due to each fault for several different samples of trial installations. Because an incident may be a first manifestation in one sample, but a repeat manifestation in another, the storage scheme must be flexible enough to handle this. Faults An incident reflects the user’s view of the system, but a fault is seen only by the developer. Thus, a fault report is organized much like an incident report but has very different answers to the same questions. It focuses on the internals of the system, looking at the particular module where the fault occurred and the cost to locate and fix it. A typical fault report interprets the eight attributes in the following way:
Changes Once a failure is experienced and its cause determined, the problem is fixed through one or more changes. These changes may include modifications to any or all of the development products, including the specification, design, code, test plans, test data and documentation. Change reports are used to record the changes and track the products most affected by them. For this reason, change reports are very useful for evaluating the most fault-prone modules, as well as other development products with unusual numbers of defects. A typical change report may look like this:
|