
Repair Detection
A set of open-source scripts and annotations for replicating or extending the experiments in our 2018 TopiCS paper - for automatic detection of self- and other-repair phenomena in conversation corpora.

Reel Reviews
Our Android app which tells you what real people think of the films currently playing in cinemas near you. (Well, provided you live in the UK). Reel Reviews mines Twitter to find people sharing their opinion on films they've recently seen, and analyses the results automatically using our statistical language tools to calculate an overall positivity rating. This turns out to be different from calculating general sentiment: people like to be scared by a horror movie, and they like to feel sad after a romantic tragedy. More information here at QApps.
 DiaSim
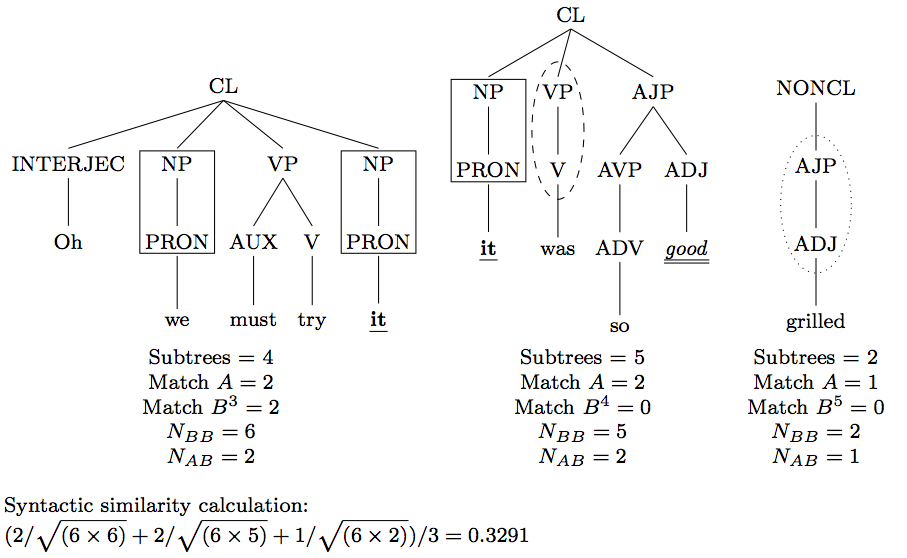
DiaSim
DiaSim ("Dialogue Similarity") is an open-source Java project for calculating lexical, syntactic and semantic similarity in dialogue corpora, including within- and between-speaker similarity and comparison to various randomly re-ordered baselines - see this paper. You can download it from SourceForge.
 Chatterbox Social Media APIs
Chatterbox Social Media APIs
Try our APIs for sentiment and emotion detection. They're free to use (as long as the data rate stays fairly low to spare our servers). If you use them in research, please cite this paper, or this paper for the Chinese versions.
 London
Emotion Map
London
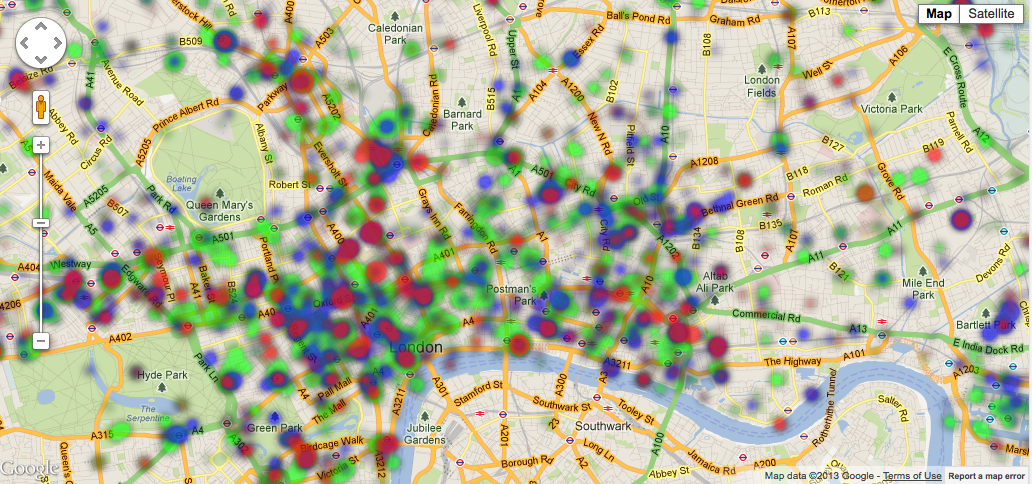
Emotion Map
Our London Twitter Emotion Map is constantly monitoring the Twitter stream in London and passing the messages through our automatic emotion detection tools (see this paper, or this paper for Chinese, and the Sentimental APIs). The APIs are free to use - if you use them in research, please cite this paper, or this paper for Chinese.
 DyLan
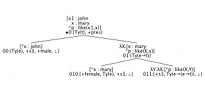
DyLan
DyLan ("Dynamics of Language") is an open-source Java implementation of Dynamic Syntax. It includes a strictly left-to-right incremental parser and generator, and is integrated into the Jindigo incremental dialogue system toolkit. You can download it from SourceForge.
 Wheel of Emotion
Wheel of Emotion
Try our National Science & Engineering Week emotion analysis demo: spin the Wheel of Emotion! It's written in Processing and should run as a Java applet within a standard browser window. You can get the code from the applet window.
 Sentimental
Sentimental
Our iPhone app which tells you what real people think about your area. Sentimental collects Twitter messages from two miles around your current location, and analyses their sentiment automatically via our Chatterbox Analytics Engine. It will then tell you how positive or negative your current area is, and which hashtags are most strongly associated with positive or negative tweets. Sentimental is now available through Apple's AppStore - more information here at QApps, and the underlying sentiment detection engine can be accessed via the Sentimental APIs on Mashape.
CLARIE
I'll bundle up the code soon(ish); in the mean time you can try the basic rule-based version here in two flavours: this one here uses a chunk parser and a simplified representation (as described in this paper); and this one here uses an HPSG grammar and horrifically complex feature-structure representations (as described in my thesis).
Dynamic Syntax
A Prolog implementation of Dynamic Syntax; should work under SICStus or SWI. The original 2003 version (as in this paper) included a parser and generator, but no notion of context for anaphora/ellipsis. The 2004 version included a simple model of context (as in this paper) so can deal with simple inter/intrasentential pronouns and VP ellipsis. The implementation is now (2008) being extended by the IMC group at Queen Mary to conform to this paper and handle more complex phenomena. You can download the source for the early versions here:
| Download: | Source code (2003 version) |
| Source code (2004 version, includes a simple model of context) |
There is also a web demo - as DS is word-by-word incremental, you can watch the semantic parse trees being built step by step. The best version to use is the one being kept up to date at QMUL, but if that's temporarily unavailable you can use the old (2004) version here:
| Try the web demo: | Current version at QMUL |
| Old backup version (2004) |
SCoRE
SCoRE is a web interface for dialogue corpora - initially the British National Corpus but now several others too - which lets you search or view them via a web browser. It is essentially just a bundle of Perl scripts, so it's much slower than the BNC's SARA (at least for simple queries), but has more search capability - it can search for any regular expression, so can e.g. search for repeats of arbitrary words/phrases, including repeats across sentence/turn boundaries. You can also browse dialogues in a nice easy-to-read way.
You can try it here if you have a licence for the BNC, but you'll need to contact me for a password first.
The manual and the "safe" version of the code below are for the initial BNC-only version (v1.1). Since then it has been much improved, both in terms of functionality and the corpora it now works with: adding CHILDES and the Rochester TRAINS dialogues for example. I never seem to have time to update the manual or package up the code properly, though, so feel free to download the latest version, but you'll need to contact me for installation instructions.
| Download: | Source code (v1.1) |
| Manual (v1.1) | |
| Source code (current version) |
OALD
The Oxford Advanced Learner's Dictionary of Current English is freely available from the Oxford Text Archive for non-commercial research purposes. It contains about 70,000 words (or about 40,000 root forms) and is in a plain ASCII text format. Information about part-of-speech, inflectional morphology, verb subcategory, pronunciation and word rarity is included.
I've processed it into a Prolog format for use in KCL's SHARDS system, and into various text versions for building dictionary-based stemmers/lemmatizers: all are available here.
| Download: | Original ASCII version |
| Prolog version & processing script | |
| A text version which pairs inflected forms with their root form (for use e.g. in a stemmer) | |
| A text version which lists root forms with their Penn-Treebank-PoS-tagged inflected forms (for use e.g. in a lemmatizer) |
frqsvr
A simple Perl word frequency tagger based on Adam Kilgarriff's BNC word frequency lists. It's designed for use in a dialogue context, so runs as a server, and clients connect via a network sockets interface. This way it only has to load the lists once, so a dialogue system can send it short sentences and get tagged versions back quickly. It's not very clever or very fast so might not be great for tagging large blocks of text - but that isn't really what it was written for.
| Download: | Source code |