Multi-View Dynamic Face Models
Yongmin Li ,
Shaogang Gong and
Heather
Liddell
- Introduction
- A Sparse 3D PDM of Faces
- A Shape-and-Pose-Free Texture Model
- Model Fitting
- Examples
- Relavant Publications
Introduction
Modelling faces under large pose variation and dynamically over time in
video sequences are two challenging problems in face recognition and facial
analysis. To address these problems, a comprehensive novel multi-view dynamic
face model is presented in this work. The model consists of a 3D shape
model, a shape-and-pose-free texture model, and an affine geometrical
model.
A Sparse 3D PDM of Faces
The 3D shape vector of a face is defined as the 3D positions of a
sparse set of landmarks. Given a set of 2D face images with known pose
and 2D positions of the landmarks, the 3D shape vector can be
estimated using linear regression. A sparse set of 44 landmarks
locating the mouth, nose, eyes, and face contour were
semi-automatically labelled on each face image. Figure 1 shows the sample face images used to
construct the model and the landmarks labelled on each image as well.
The 3D shape estimated from these labelled face images is shown in
Figure 2
with tilt fixed on 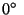 and yaw changing from
and yaw changing from 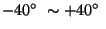 .
.
![\includegraphics[width=.80\textwidth]{figures/shapevec.eps}](img30.gif)
|
Figure 2: A 3D shape vector
estimated from the face images shown in Figure 1.
The Point Distribute Model (PDM) is adopted in this work to
further reduce the dimensionality of shape space. We trained the PDM
on a set of 600 3D shape vectors from 12 different subjects (50 of
each subject). Each 3D shape vector was estimated from a random
selection of 20 of 45 face images of the same subject. After training,
the first 10 eigenshapes take 95.5% of all variance.
A Shape-and-Pose-Free Texture Model
We present a statistical approach to model face textures by extracting
shape-and-pose-free texture information. To decouple the
covariance between shape and texture, a face image fitted by the shape
model is warped to the mean shape at frontal view (with in both tilt and yaw). This
is implemented by forming a triangulation from the landmarks and
employing a piece-wise affine transformation between each triangle
pair. By warping to the mean shape, one obtains the shape-free
texture of the given face image. Furthermore, by warping to the
frontal view, a pose-free texture representation is
achieved. Figure 3 illustrates the
shape-and-pose-free texture patterns of the face images shown
in Figure 1.
![\includegraphics[width=.08\textwidth]{figures/warp00.eps}](img40.gif) ![\includegraphics[width=.08\textwidth]{figures/warp01.eps}](img41.gif) ![\includegraphics[width=.08\textwidth]{figures/warp02.eps}](img42.gif) ![\includegraphics[width=.08\textwidth]{figures/warp03.eps}](img43.gif) ![\includegraphics[width=.08\textwidth]{figures/warp04.eps}](img44.gif) ![\includegraphics[width=.08\textwidth]{figures/warp05.eps}](img45.gif) ![\includegraphics[width=.08\textwidth]{figures/warp06.eps}](img46.gif) ![\includegraphics[width=.08\textwidth]{figures/warp07.eps}](img47.gif) ![\includegraphics[width=.08\textwidth]{figures/warp08.eps}](img48.gif)
|
Figure 3: Extract the
shape-and-pose-free texture patterns of the face images shown
in Figure 1.
We applied a PCA to a set of 540 shape-and-pose-free face
textures from 12 subjects.The first 12 eigen modes take 96.4% of all
variance.
Model Fitting
Model fitting is
performed by optimising a global appearance fitting criterion,
a local fitting criterion on landmarks, and a temporal
fitting criterion between successive frames in a video sequence. After
fitting the multi-view face model to a given image or video sequence
containing faces, one receives the following set of parameters: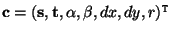 where
s is the shape parameter, t is the shape-and-pose-free
texture parameter,
where
s is the shape parameter, t is the shape-and-pose-free
texture parameter, 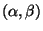 is pose in tilt and yaw
estimated by an SVM (Support Vector Machine) based pose
estimator, (dx,dy) is the translation of the centroid of
the face, and r is its scale.
is pose in tilt and yaw
estimated by an SVM (Support Vector Machine) based pose
estimator, (dx,dy) is the translation of the centroid of
the face, and r is its scale.
Therefore, this model
provides the identity information (s, t) of a face which is crucial to
face recognition and facial analysis, and the geometrical information
(the remaining part) which can be used for face tracking and
alignment.
Examples
-
The process of fitting the model to a face image.
![\includegraphics[width=.4\textwidth]{figures/jamiefit/before.eps}](fig2/img52.gif) ![\includegraphics[width=.4\textwidth]{figures/jamiefit/after.eps}](fig2/img53.gif) ![\includegraphics[width=.1\textwidth]{figures/jamiefit/iter01.eps}](fig2/img54.gif) ![\includegraphics[width=.1\textwidth]{figures/jamiefit/iter02.eps}](fig2/img55.gif) ![\includegraphics[width=.1\textwidth]{figures/jamiefit/iter03.eps}](fig2/img56.gif) ![\includegraphics[width=.1\textwidth]{figures/jamiefit/iter04.eps}](fig2/img57.gif) ![\includegraphics[width=.1\textwidth]{figures/jamiefit/iter06.eps}](fig2/img58.gif) ![\includegraphics[width=.1\textwidth]{figures/jamiefit/iter07.eps}](fig2/img59.gif) ![\includegraphics[width=.1\textwidth]{figures/jamiefit/iter08.eps}](fig2/img60.gif) ![\includegraphics[width=.1\textwidth]{figures/jamiefit/iter10.eps}](fig2/img61.gif) |
Figure 4: Fit the multi-view face model
to a face image. The first two images shows the original face image and
the fitted pattern warped on the original image. The others are the fitting
results in 8 iterations.
-
Fit the model to a sequence containing faces with large pose variation
(nearly profile to profile). The length of the sequence is 81 frames.
-
Fit the model to a sequence containing faces with significant
expression change. The length of the sequence is 47 frames.
Relavant Publications
-
Y. Li, S. Gong, and H. Liddell.
Modelling
faces dynamically across views and over time.
Technical
report, Queen Mary, University of London, 2001.
-
Y. Li, S. Gong, and H. Liddell.
Support
vector regression and classification based multi-view face detection and
recognition.
In IEEE International Conference on Automatic Face & Gesture
Recognition, pages 300-305, Grenoble, France, 2000.
Yongmin Li 2001-02-05