Software measurement activities related to QA in the life-cycleIn this section we put these ideas together by explaining how the various metrics activities relate to the QA activities within the life-cycle. Cost and effort estimationStarting at the requirements phase (but usually needing to be repeated at each major subsequent review) managers must plan projects by predicting necessary cost and effort and assigning resources appropriately. Doing this accurately has become one of the ‘holy grail’ searches of software engineering. The desire by managers for improved methods of resource estimation provided one of the original motivations for deriving and using software measures. As a result, numerous measurement-based models for software cost and effort estimation have been proposed and used. Examples include Boehm’s COCOMO model, Putnam’s SLIM model and Albrecht’s function points model. These models share a common approach: effort is expressed as a (pre-defined) function of one or more variables (such as size of the product, capability of the developers and level of reuse). Size is usually defined as (predicted) lines of code or number of function points (which may be derived from the product specification). There is no definitive evidence that using models such as these does lead to improved predictions. However, the predictive accuracy of all of the models is known to improve if a data-base of past projects (each containing the same variables used in the models, such as effort and size) is available. The availability of such a database can lead to reasonably accurate predictions just using standard statistical regression techniques [Kitchenham and de Neumann 1990]. This suggests that the models may be redundant in such situations, but the models may still be extremely useful in the absence of such data. Moreover, the models have had an important historical impact on software metrics, since they have spawned a range of measures and measurement techniques which have impacted on QA activities far removed from resource estimation. Productivity models and measures Resource estimation (and indeed post-project process improvement planning) can only be done effectively if something is known about the productivity of software staff. Thus, the pressing needs of management have also resulted in numerous attempts to define measures and models for assessing staff productivity during different software processes and in different environments.
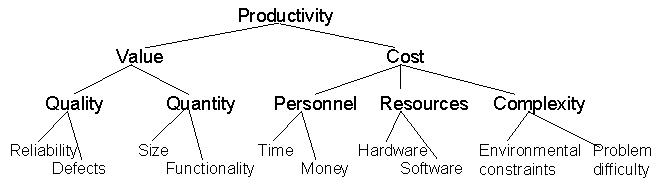
Figure 3.1: A productivity model Figure 3.1 illustrates an example of the possible components that contribute to overall productivity. It shows productivity as a function of value and cost; each is then decomposed into other aspects, expressed in measurable form. This model is a significantly more comprehensive view of productivity than the traditional one, which simply divides size by effort. That is, many managers make decisions based on the rate at which lines of code are being written per person-month of effort. This simpler measure can be misleading, if not dangerous for reasons that we discuss in Section 4. Nevertheless, it is interesting to note that even this crude measure of software productivity (which is used extensively in the software industry) implies the need for fairly extensive measurement. Data collectionWe have argued that measurement is the key factor in any software quality assurance program. But effective use of measurement is dependent on careful data collection, which is notoriously difficult, especially when data must be collected across a diverse set of projects. Thus, data collection is becoming a discipline in itself, where specialists work to ensure that measures are defined unambiguously, that collection is consistent and complete, and that data integrity is not at risk. But it is acknowledged that metrics data collection must be planned and executed in a careful and sensitive manner. Data collection is also essential for scientific investigation of relationships and trends. Good experiments, surveys and case studies require carefully-planned data collection, as well as thorough analysis and reporting of the results. In Section 6 we focus on one of the most important aspects of data collection for software measurement and QA: how to record information about software faults, failures and changes Quality models and measuresNo quantitative approach to software QA can be complete without a measurable definition of software product quality. We can never know whether the quality is satisfactory or improving if we cannot measure it. Moreover, we need quality measures if we are to improve our resource estimation and productivity measurement. In the case of resource estimation, higher quality requirements may lead to greater resources. In the case of productivity measurement, speed of production is meaningless without an accompanying assessment of product quality. Thus work on resource estimation and productivity assessment inspired software engineers to develop models of quality which took into account various views of software quality. For example, Boehm’s advanced COCOMO cost estimation model is tied to a quality model. Similarly, the McCall quality model [McCall 1977], commonly called the FCM (Factor Criteria Metric) model, is related to productivity.
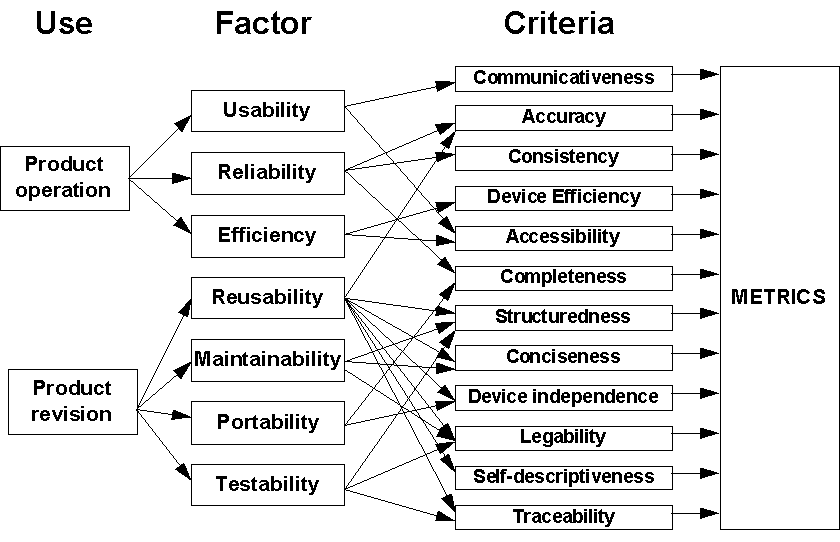
Figure 3.2: Software quality model These models are usually constructed in a tree-like fashion, similar to Figure 3.2. The upper branches hold important high-level quality factors of software products, such as reliability and usability, that we would like to quantify. Each quality factor is composed of lower-level criteria, such as modularity and data commonality. The criteria are easier to understand and measure than the factors; thus, actual measures (metrics) are proposed for the criteria. The tree describes the pertinent relationships between factors and their dependent criteria, so we can measure the factors in terms of the dependent criteria measures. This notion of divide-and-conquer has been implemented as a standard approach to measuring software quality [ISO 9126] which we shall discuss this in depth in Section 7.3. Quality models are expected to be used at the specification and design phase of software QA. The idea is that targets for the high level factors are set, while assessments of the likeliness of meeting these targets is based on measuring the lower level criteria during design. Reliability modelsMost quality models include reliability as one of its component factors. But the need to predict and measure reliability itself has led to a separate specialization in reliability modeling and prediction. [Littlewood 1988] and others provide a rigorous and successful example of how a focus on an important product quality attribute has led to increased understanding and control of our products. The software reliability modelling work is applicable during the implementation phase of software QA. Specifically the models work well when it is possible to observe and record information about software fialures during test or operation. A detailed account of software reliability modelling is beyond the scope of this chapter. Interested readers should refer to [Lyu 1996] for a comprehensive account. Performance evaluation and modelsPerformance is another aspect of quality. Work under the umbrella of performance evaluation includes externally-observable system performance characteristics, such as response times and completion rates. In this respect performance modelling only makes sense as part of the implementation and maintenance phases of software QA. However, performance specialists also investigate the internal workings of a system and this is relevant at the specification and design phase for software QA. Specifically this includes the efficiency of algorithms as embodied in computational and algorithmic complexity (see, for example [Harel 1992]) The latter is also concerned with the inherent complexity of problems measured in terms of efficiency of an optimal solution. Structural and complexity metricsDesirable quality attributes like reliability and maintainability cannot be measured until some operational version of the code is available. Yet we wish to be able to predict which parts of the software system are likely to be less reliable, more difficult to test, or require more maintenance than others, even before the system is complete. As a result, we measure structural attributes of representations of the software which are available in advance of (or without the need for) execution; then, we try to establish empirically predictive theories to support quality assurance, quality control, and quality prediction. Halstead [Halstead 1975] and McCabe [McCabe 1976] are two classic examples of this approach; each defines measures that are derived from suitable representations of source code. This class of metrics, which we discuss in Section 5.1 is applicable during various software QA phases. Management by metricsMeasurement is becoming an important part of software project management. Customers and developers alike rely on measurement-based charts and graphs to help them decide if the project is on track. Many companies and organizations define a standard set of measurements and reporting methods, so that projects can be compared and contrasted. This uniform collection and reporting is especially important when software plays a supporting role in the overall project. That is, when software is embedded in a product whose main focus is a business area other than software, the customer or ultimate user is not usually well-versed in software terminology, so measurement can paint a picture of progress in general, understandable terms. For example, when a power plant asks a software developer to write control software, the customer usually knows a lot about power generation and control, but very little about programming languages, compilers or computer hardware. The measurements must be presented in a way that tells both customer and developer how the project is doing. Evaluation of methods and toolsThere are many people who believe that significant improvements in software quality can only come about by radical technological improvements. Techniques such as CASE tools and object-orientation are ‘sold’ in this way. The literature is rife with descriptions of new methods and tools that may make your organization or project more productive and your products better and cheaper. But it is difficult to separate the claims from the reality. Many organizations perform experiments, run case studies or administer surveys to help them decide whether a method or tool is likely to make a positive difference in their particular situations. These investigations cannot be done without careful, controlled measurement and analysis. An evaluation’s success depends on good experimental design, proper identification of the factors likely to affect the outcome, and appropriate measurement of factor attributes. Capability maturity assessmentIn the 1980s, the US Software Engineering Institute (SEI) proposed a capability maturity model (CMM) [Humphrey 1989] to measure a contractor’s ability to develop quality software for the US government. The CMM assessed many different attributes of development, including use of tools and standard practices. CMM has rapidly becoming an internationally recognised model for software process improvement. It has had a major impact on awareness and take-up of metrics for QA, because metrics are identified as important for various levels of process imporvement. In the frameworks and standards section we discuss CMM and other process improvement models in some depth. |