The alternative way of storing a collection of data is to use a
linked cells data structure. A linked cells data structure is one
where an object of class C contains some fields storing data and
some fields which are themselves of class C. For now we shall
keep to the simplest type of linked cell structure, the linked list.
A linked list is an object which has two fields: one a piece of data, the
other a linked list. You may wonder how can a linked list have a linked list
inside it. Surely the linked list inside will also have a further linked list
inside itself, and that linked list will have one inside itself, and so
on for ever.
The solution to this problem is that any object variable or field may have the
special value null, which means "refers to no data". For example,
an object field which has not been set a value will be given the value
null. If an object variable v is set to
null, any attempt to refer to a field of it such as
v.somefield, or use a method attached to it, such as
v.somemethod() will cause an exception of the type
NullPointerException to be thrown. In a linked list, eventually
if we keep following the list inside the list inside the list, we will get to
a list field which has the value null, so it refers to no data.
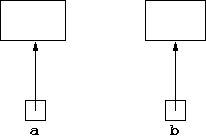
For example, suppose we have two variables a and b
of some object type ObjType. They are declared as:
ObjType a,b;but
a and b can't be considered as pointing to
anything until the object values are created with new, or they
are set to point to some existing object value. The situation after both
a and b are set to new values with:
a = new ObjType(); b = new ObjType();can be represented by:
The small boxes represent a part of the computer memory holding the reference
to an object, the big boxes represent the part of the computer memory holding
the actual data of an object.
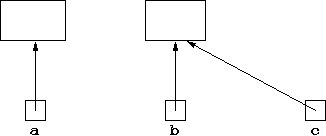
Suppose we have another variable, c of type ObjType,
declared by:
ObjType c;and set to be an alias of
b (remember assignment is aliasing with
objects) by:
c = b;Thinking of this as aliasing, we said this meant
b and
c are two names for the same object. Another way of thinking
of this is to say that b and c point to the same
object, as in:
Now if we do:
b = a;the effect is that
b no longer points to what it used to, but
instead points to what a points to. Meanwhile, c
continues to point to what b used to point to:
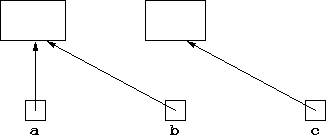
If however, we then set c to point to something new, by:
c = new ObjType();the effect is that nothing points to what
b originally pointed to,
and then c was set to point to:
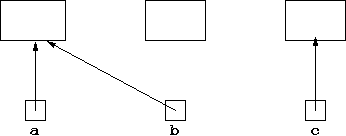
There is no way of getting to the box that b originally
pointed to, and c was first set to point to (unless another
variable was set to point to it). In Java, data which is no longer pointed
to like this is automatically recycled so the actual computer memory used for
it may be reused next time a new call is made. This process of
recycling is known as garbage collection. In many other languages
(like C) it is necessary for the programmer to write a special command to
cause garbage collection to happen.
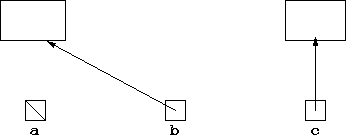
As mentioned previously, any object variable may be set to null
meaning it refers to no data. This can be illustrated diagramatically
by something like an electrical earth sign:
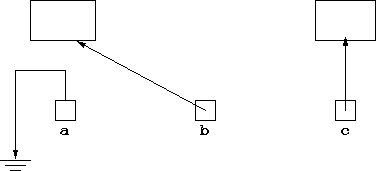
but more usually it is done by just putting a bar through the box representing the pointer of the variable:
class StudentList
{
Student head;
StudentList tail;
StudentList(Student h,StudentList t)
{
head=h;
tail=t;
}
}
Then a StudentList object L has two parts,
L.head which is a Student object, and
L.tail which is itself a StudentList object.
We could show this diagrammatically by having L point to a
box with two parts:
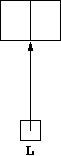
But as L.tail refers to a StudentList object, it
has two parts itself: L.tail.head and L.tail.tail,
and since L.tail.tail is a StudentList object,
it has two parts, and so on. Eventually the chain ends when we get to a
.tail part which is set to null rather than pointing
to further data. This chain can be represented diagrammatically as:
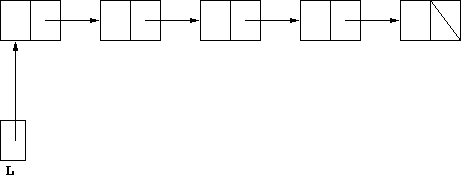
Note the arrows here point to the box as a whole (each containing two fields),
not to an individual field of the box. The left-hand side of each box
represents a student record (i.e. a field of type Student), the
right-hand side of each box represents a StudentList reference.
The diagram represents a list of five students. Suppose these students
are named a, b, c, d and e, giving us the
structure:
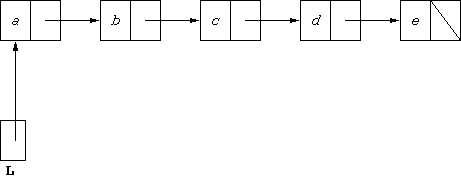
Then we can think of this structure as representing the list which we could
write [a,b,c,d,e] (this notation is simply the way we choose to write
it and is nothing to do with the Java representation). L can be
thought of as storing this list, then L.head stores student
record a, while L.tail stores the list [b,c,d,e].
L.tail.head stores student record b while
L.tail.tail stores the list [c,d,e]. If we have another
variable of type StudentList, called L1, if we
execute the assignment:
L1 = L.tail.tail;we will get the structure:
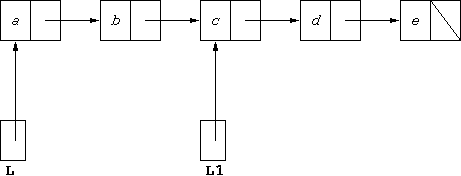
Note this means that L and L1 point to
different parts of the same data structure. If we were to execute
L1.head = x;where
x is some value of type Student, the
resulting structure would have the form:
so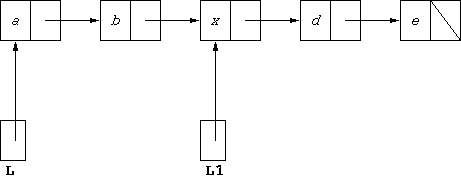
L1 then represents [x,d,e], but also, L
then represents [a,b,x,d,e].
L1.tail.tail represents the list consisting of just e.
If we execute:
L1.tail = L1.tail.tail;the results will be that
L1.tail changes from representing
[d,e] to representing [e]. Since the structure is shared with
L, it will also result in L changing from
representing [a,b,x,d,e] to representing [a,b,x,e].
Diagrammatically, the effect of the assignment L1.tail=L1.tail.tail
is:
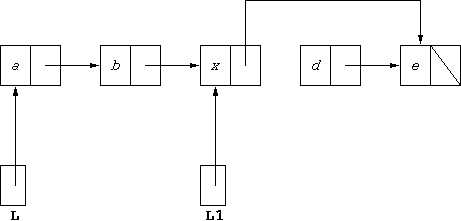
Assuming nothing else points to the box that stores d, that store will be recycled, and the above is equivalent to:
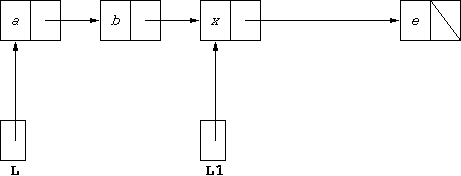
If we execute:
L = new StudentList(y,L);the result is that
L references a new StudentList
whose head is y and whose tail is the old value of L.
Following on from where we were last, that means L changes from
representing [a,b,x,e] to representing [y,a,b,x,e],
diagrammatically:
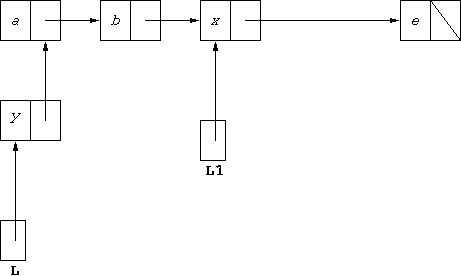
Student objects may be used to represent
a database of students. In order to maintain compatibility with the
previous examples in student database part 1
, we shall again have a class for the student database which
implements the Database interface. Having this means even
though the database is implemented completely differently, using a linked
list rather than an array, the original StudentDatabaseUse
program can be easily changed to use it, just by changing
StudentDatabase1 on line 27 to StudentDatabase5.
Here is the code for StudentDatabase5:
1 class StudentDatabase5 implements Database
2 {
3 // Implemented with an unordered linked list
4
5 private StudentList students;
6
7 public StudentDatabase5()
8 {
9 students=null;
10 }
11
12 public void insert(Object obj) throws FullUpException
13 {
14 StudentList newstudents;
15 try {
16 newstudents = new StudentList((Student)obj,students);
17 students=newstudents;
18 }
19 catch(OutOfMemoryError e)
20 {
21 throw new FullUpException();
22 }
23 }
24
25 public void delete(String key) throws NotFoundException
26 {
27 StudentList ptr;
28 if(students==null)
29 throw new NotFoundException(key);
30 if(students.head.equalKey(key))
31 {
32 students=students.tail;
33 return;
34 }
35 if(students.tail==null)
36 throw new NotFoundException(key);
37 for(ptr=students;ptr.tail!=null;ptr=ptr.tail)
38 if(ptr.tail.head.equalKey(key))
39 {
40 ptr.tail=ptr.tail.tail;
41 return;
42 }
43 throw new NotFoundException(key);
44 }
45
46 public Object retrieve(String key) throws NotFoundException
47 {
48 StudentList ptr;
49 for(ptr=students;ptr!=null;ptr=ptr.tail);
50 if(ptr.head.equalKey(key))
51 return ptr.head;
52 throw new NotFoundException(key);
53 }
54
55 public void list()
56 {
57 StudentList ptr;
58 for(ptr=students;ptr!=null;ptr=ptr.tail)
59 System.out.println(ptr.head);
60 }
61
62 private static class StudentList
63 {
64 Student head;
65 StudentList tail;
66
67 StudentList(Student h,StudentList t)
68 {
69 head=h;
70 tail=t;
71 }
72 }
73
74 }
This class makes use of a new concept, an inner class. Lines 62 to
72 show the inner class StudentList. As you can see, the
complete code for this class is inside the class
StudentDatabase5 (whose closing bracket is on line 74). As it is
private it may only be referred to inside the class StudentDatabase5.
So StudentDatabase5 presents to the outside world the
familiar database methods we saw previously, and keeps to itself its
list representation. This is an extension of data hiding: now a complete
class is being hidden. This helps structure the program, making it clear the
type StudentList is for use only with the StudentDatabase5
class. If it were a separate class in a separate file, that link might not
be so apparent.
An object of type StudentDatabase5 keeps its own list of
students in field students declared on line 5. The fact that
Students is private prevents it being manipulated by other
objects. As the examples shown above with diagrams indicate, unrestricted
access to lists can cause complications as changes intended for one
list can affect another which shares its data. Here only the
StudentDatabase5 object can manipulate its own list, which it
does with its methods. There is no danger caused by the list being shared
with some other object. It also overcomes the otherwise rather awkward
problem of representing the empty database. An empty list could be
represented by null, but no methods can be performed on an
object variable which is set to null (an attempt to do so will
result in a NullPointerException). However, a StudentDatabase5
object whose private students list is set to null
represents the empty database of students, but can have all the normal methods
applied to it.
The methods insert and delete change the
internal list students. It cannot be changed in any other way.
The insert method changes it in a way similar to that we used to
change what L referred to above, adding the new student
y.
The delete method is a little more
complex. It works in a way similar to that used to cut the student
d from out of the list L above. In order
to cut an element out of a linked list, we need to have something that points
to the element before it, as L1 pointed to the element
before d above. In delete the variable
used to point to the element before the element to be deleted is called
ptr (a common name for such a pointer used in linked structure
manipulation). Lines 37-42 give a loop where ptr is made to
move down the linked list until it points to the last element, or until the
element after the one it points to is the one to be deleted. In this latter
case, the condition on line 38 becomes true, meaning line 40 is executed
(cutting out the element) and then line 41, which being return
causes the method to be halted immediately. Only if the loop is not halted
and left in this way is line 43 ever reached. So when line 43 is reached it
must be because no student with the name to be deleted was found, so a
NotFoundException is thrown.
Because deleting an element from a linked list involves having a pointer to the
element before it in the list, a special case has to be made when the element
being deleted is the first element in the list. In delete this
special case is dealt with on lines 30-34.
When dealing with linked lists, the pattern of starting a pointer
pointing to the first element of a list, and then moving it down the list
using ptr=ptr.tail is a common one. It is used again in the
method retrieve which returns the complete student record
of a student with the name given as its argument. The common pattern
has a general header:
for(ptr=L; condition; ptr=ptr.tail)where
L is the list being moved down. In the example given
here, retrieve, like delete uses the technique
that the loop is finished early when a return is encountered
in its body. An alternative way of writing retrieve which
did not use this trick would look like:
public object retrieve(String key) throws NotFoundException
{
StudentList ptr;
for(ptr=students; ptr!=null&&!ptr.head.equalKey(key); ptr=ptr.tail);
if(ptr==null)
return new NotFoundException(key);
else
return ptr.head;
}
Note that this makes use of a loop with no body (shown by the semicolon at the
end of the line beginning for) and it is necessary to use
&& in the condition to show how it can be exited in two
different ways. Here the sequential operation of && is
essential - if ptr becomes null, the loop
is on the left-hand side of the && becomes false
without even trying the right-hand side, which is just as well as the
right-hand side can't be correctly executed if pre is
null.
Because linked lists only take up enough store to store the actual data in
them, and more store is taken just when needed, the storage problems we had
with implementing a database with an array no longer occur. We don't have
to reserve space as big as we think we might ever need. Nor do we have to have
a fixed limit, beyond which no more records can be stored. When we had this
fixed limit with arrays and it was exceeded, we threw a
FullUpException. It is however, possible for the whole
computer to run out of memory, which causes a problem when more store is
allocated using a new command. In Java when this happens
a OutOfMemoryError occurs. This can be caught like an
exception. You are unlikely to see this error happen during the normal
course of the sort of program you will be writing in this course - the
computers have plenty enough memory for the amount of data you are going to
want to store. If you do get an OutOfMemoryError it is almost
certainly because you have written a program with an inifinite loop or
infinite recursion where each step round the loop or recursion takes some
more memory. However, for completeness the method insert in
StudentDatabase5 can catch a OutOfMemoryError
(on line 19) and convert it to a FullUpException by throwing a new
FullUpException (on line 21). It is, for the reasons
explained, much less likely that StudentDatabase5 will throw
a FullUpException than the previous student database examples.
1 class StudentDatabase6 implements Database
2 {
3 // Implemented with a linked list ordered by name
4
5 private StudentList students;
6
7 public StudentDatabase6()
8 {
9 students=null;
10 }
11
12 public void insert(Object obj) throws FullUpException
13 {
14 Student student=(Student)obj;
15 StudentList ptr;
16 try {
17 if(students==null)
18 students = new StudentList(student,null);
19 else if(student.beforeAlphabetically(students.head))
20 students = new StudentList(student,students);
21 else
22 {
23 for(ptr=students;
24 ptr.tail!=null&&ptr.tail.head.beforeAlphabetically(student);
25 ptr=ptr.tail);
26 ptr.tail = new StudentList(student,ptr.tail);
27 }
28 }
29 catch(OutOfMemoryError e)
30 {
31 throw new FullUpException();
32 }
33 }
34
35 public void delete(String key) throws NotFoundException
36 {
37 StudentList ptr;
38 if(students==null)
39 throw new NotFoundException(key);
40 if(students.head.equalKey(key))
41 {
42 students=students.tail;
43 return;
44 }
45 for(ptr=students;
46 ptr.tail!=null&&ptr.tail.head.name.compareTo(key)<0;
47 ptr=ptr.tail);
48 if(ptr.tail==null)
49 throw new NotFoundException(key);
50 else if(ptr.tail.head.equalKey(key))
51 ptr.tail=ptr.tail.tail;
52 else
53 throw new NotFoundException(key);
54 }
55
56 public Object retrieve(String key) throws NotFoundException
57 {
58 StudentList ptr;
59 for(ptr=students;
60 ptr!=null&&ptr.head.name.compareTo(key)<0;
61 ptr=ptr.tail);
62 if(ptr==null||!ptr.head.equalKey(key))
63 throw new NotFoundException(key);
64 return ptr.head;
65 }
66
67 public void list()
68 {
69 StudentList ptr;
70 for(ptr=students;ptr!=null;ptr=ptr.tail)
71 System.out.println(ptr.head);
72 }
73
74 private static class StudentList
75 {
76 Student head;
77 StudentList tail;
78
79 StudentList(Student h,StudentList t)
80 {
81 head=h;
82 tail=t;
83 }
84 }
85
86 }
In this version, when we are moving the pointer down a list to retrieve or
delete a record, we stop if we go beyond the point where the record
would be found alphabetically as we know it won't be found past there.
Inserting a new record is rather more complex than before, however. We no
longer add it to the front of the list, but find the appropriate place to
insert it, again by moving a pointer down the list. Lines 23-25 are
the for loop that does this. The for loop has no body, but exits either when
the pointer is pointing to the last item in the list (so ptr.tail
is null), or when the item after the one it is pointing to is
no longer less than the one being inserted alphabetically. In either case, the
pointer is then pointing to the right place for insertion to take place.
To illustrate the effect of inserting into an ordered list, suppose the list is [a,b,c,e,f], and we want to insert d, assuming the letters used here represent the correct alphabetic orderihng for the data. This is the initial state diagramatically:
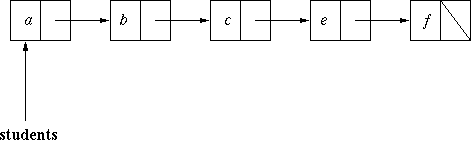
Now here is the state after ptr has been moved to point to the
insertion point, that is after the loop on lines 23-25 has exited:
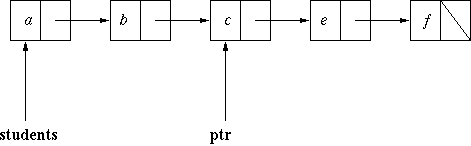
Now here is the state after executing line 26 (where the variable
student holds the record for d):
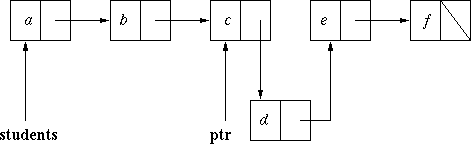
At this point, ptr.tail was referring to [e,f] and it
is changed to refer to [d,e,f]. As you can see, the effect is that the
field students (which will be inside a
StudentDatabase6 object) is changed from referring to the list
[a,b,c,e,f] to referring to the list [a,b,c,d,e,f].
These notes were produced as part of the course Introduction to Programming as it was given in the Department of Computer Science at Queen Mary, University of London during the academic years 1998-2001.
Last modified: 17 March 2000