The most important thing is to note that a method call runs in its own environment. It has its own variables which it uses, comprising those which are its parameters and any further declared in the code of the method as local variables. Each time a method call is made, a new set of variables is set up with those names, they are not the same variables as existed with previous calls to the same method. When a method call finishes, the execution mechanism goes back to the code where the method call was made and continues executing it in the old environment that existed before the method call was made, possibly updated by the value the method call returned being assigned to a variable in that environment.
The same applies when a method "calls itself". A new environment is set up with new variables having the same names as the previous variables but not necessarily the same values. When the recursive call finished, the execution mechanism returns to the old environment with the variables in that environment having the values they had before the recursive call was made, possibly changed by the result of the recursive call being assigned to a variable in that environment.
Let us consider the method append, which we saw previously,
used to join two Lisp lists together:
public static <T> LispList<T> append(LispList<T> ls1,LispList<T> ls2)
// Join ls1 to ls2 (implemented using recursion)
{
if(ls1.isEmpty())
return ls2;
else
{
T h = ls1.head();
LispList<T> ls3 = append(ls1.tail(),ls2);
return ls3.cons(h);
}
}
This method, and support code to test it can be found in
UseLispLists8.java
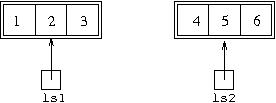
Now let us consider the situation where we are appending two Lisp lists,
one with the textual representation [1,2,3], the other
[4,5,6]. When the call to the append method is
made, initially the environment will consist of two variables referring
to these two Lisp lists:
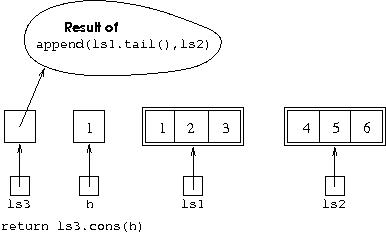
Execution of the method checks that ls1 does not refer
to an object representing the empty list. As it does not, it goes on
to the else part of the conditional statement. Here an
additional variable, h is added to the environment and
set to the head of the list referred to by ls1, that is
to 1. A variable ls3 is set up, ready to be
assigned the result of the recursive call. When the recursive call is
finished, the statement return ls3.cons(h) will be
executed, and the append call will return its result. This
can be shown diagrammatically by:
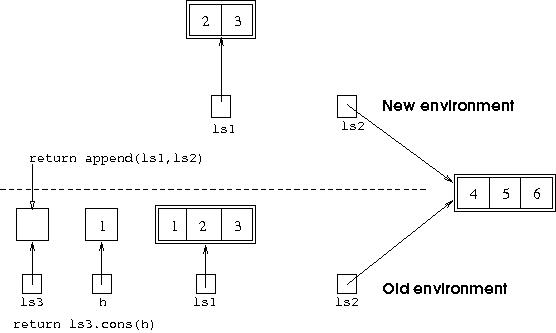
The recursive call append(ls1.tail(),ls2) will set up
its own environment for execution, with its own ls1 and
ls2. In this environment, ls1 will refer
to the first argument to the recursive call, and ls2 will
refer to the second argument. So the new ls1 refers to an
object which is the tail of the old ls1 (textually
represented by [2,3]), and the new ls2
refers to the same object as the old ls2. This can be
shown diagrammatically as:
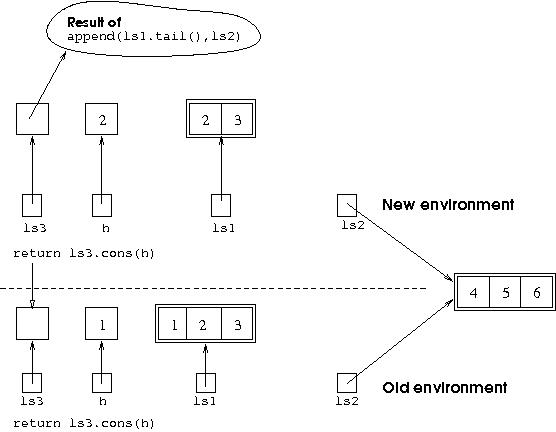
Now the same process as before takes place. The new ls1
is tested to see if it refers to an empty list object. As it does not,
the else part of the conditional statement is executed,
causing a new variable h to be added to the new environment,
set to the head of the list referred to by the new ls1, and a
new ls3 is set up, set to refer to the result of the call
to append(ls1.tail(),ls2) in the new environment. This can
be represented diagrammatically as:
The call of append(ls1.tail(),ls2) in this environment sets
up another environment, with its own ls1 and ls2.
In this environment, ls1 refers to the tail of what
ls1 referred to in the previous environment, which was the
tail of what ls1 referred to in the environment before that.
So ls1 in this latest environment refers to the list written
textually as [3], that is the list of one element where that
element is 3. The variable ls2 in this latest
environment is a separate variable from the ls2 in the
previous environment, but it refers to the same object. As ls1
does not refer to the empty list, as before, a new variable h is
set up to store its head, a new variable ls3 is set up
to store the result of the recursive call append(ls1.tail(),ls2),
and ls3.cons(h) is what is to be returned after the recursive call
finishes. This can be represented diagrammatically as:
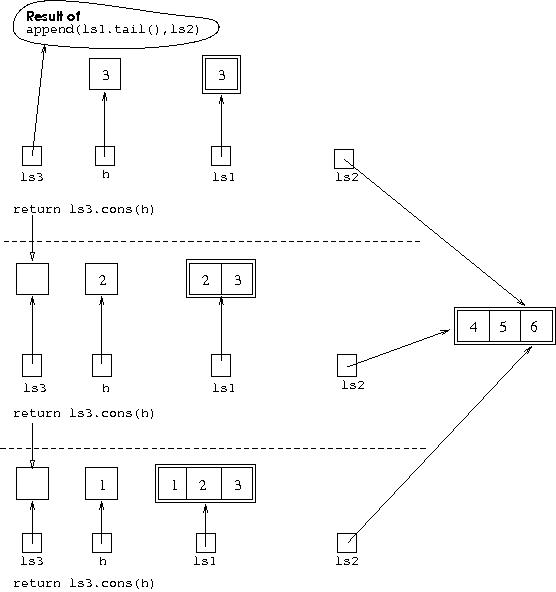
For this latest recursive call, again a new environment is set up,
containing initially two new variables, ls1 and
ls2. But now we have hit the base case, since ls1
refers to the empty list. In this case, ls2 is returned
as the result of the call, there is no recursive call made. This situation
is shown in
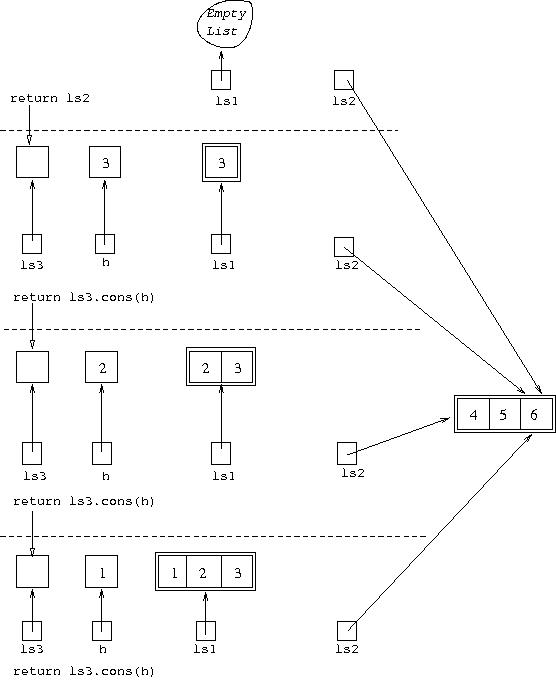
So the return from this latest call results in ls3 in the
previous call being set to ls2 in the latest call, which
is [4,5,6]. This situation is shown in:
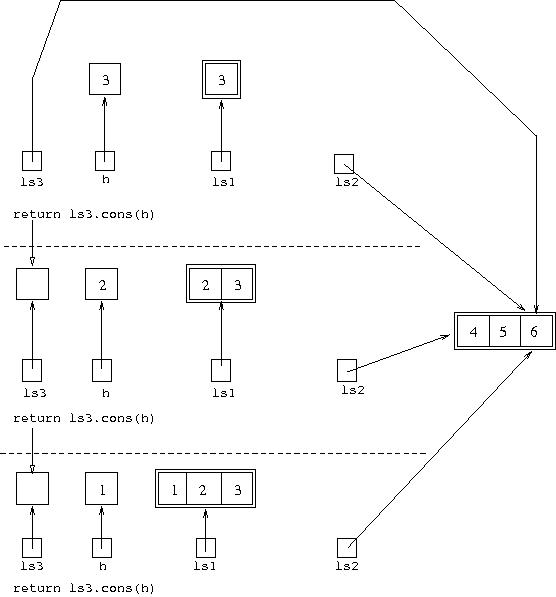
The code left to execute in the environment returned to is
return ls3.cons(h), and in this environment,
ls3 has the value [4,5,6] and
h stores 3. So l3.cons(h)
returns the value [3,4,5,6], and this value is returned
to the previous remaining environment to be assigned to its variable
ls3. This gives the situation:
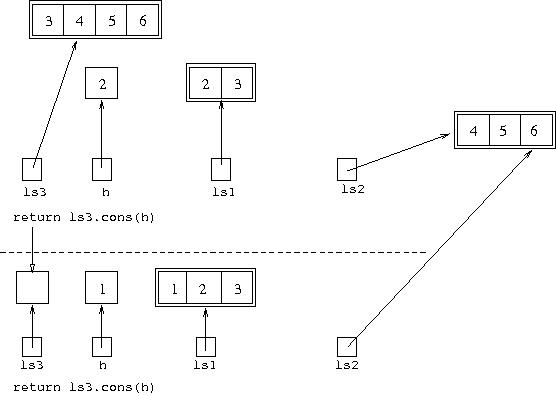
The same happens in this environment: ls3 has the value
[3,4,5,6] and h has the value 2.
So ls3.cons(h) has the value [2,3,4,5,6],
and executing return ls3.cons(h) causes this method
call to finish and return [2,3,4,5,6]. Now execution returns
back to the environment of the initial call to append where
ls3 is assigned this value returned by the recursive call.
Diagrammatically, the situation is:
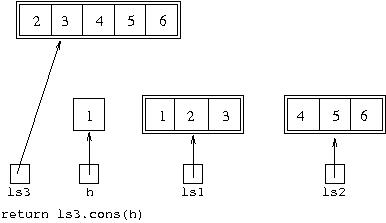
In this environment, h is 1, so returning
ls3.cons(h) returns [1,2,3,4,5,6] (or, strictly,
a reference to an object whose textual representation is
[1,2,3,4,5,6].
So you can see, step-by-step, the stages which cause [1,2,3]
to be appended to [4,5,6] to give [1,2,3,4,5,6].
You can see that environments are built up where a separate variable
h in each environment in takes the next value from the original
first list argument. Then in returning from the recursive calls a new list
is built up by joining the h from each environment to the list
returned from the previous environment.
Now let us consider the same operation implemented using the "stack and reverse" technique:
public static <T> LispList<T> append(LispList<T> ls1,LispList<T> ls2)
// Join ls1 to ls2 (implemented using iteration)
{
LispList<T> ls4 = LispList.empty();
for(;!ls1.isEmpty(); ls1=ls1.tail())
{
T h = ls1.head();
ls4 = ls4.cons(h);
}
LispList<T> ls3 = ls2;
for(;!ls4.isEmpty(); ls4=ls4.tail())
{
T h = ls4.head();
ls3 = ls3.cons(h);
}
return ls3;
}
Note that really we do not need a separate variable ls3
which is initially set to be an alias of ls2 and then gets
changed. We could just re-use the variable ls2, as its
original value is not required again in the method. Changing what ls2
refers to in the method does not change what the variable used as the second
argument to the method call refers to outside the method, since ls2
in the method code is a separate variable in a separate environment.
However, it helps the explanation given below to have a separate variable
ls3. In the version of the method given in the file
UseLispLists9.java,
the variable ls2 is reused, the file also has support code
to enable you to test the method.
What is happening in the recursive version is that the values of
h in each environment can be considered as forming a
list which works like the list given by the variable ls4
in the iterative implementation of append. The first for-loop
in the iterative version is the equivalent of going down to the base case
in the recursive version. Whereas in the recursive version there is in
fact a new variable ls1 for each recursive call, in each call
referring to a list one item shorter than the ls1 of the
previous call, in the iterative version there is just one ls1
variable which is changed each time round the loop to refer to a list
one element shorter than before. In the recursive version, there is a new
variable ls2 for each recursive call even though all these
ls2 variables refer to the same object, in the iterative version
there is just one variable ls2 throughout which always refers
to the same object.
The second for-loop in the iterative version is the equivalent of coming back up
from the base case returning to finish off previous calls in the
recursive version. In the recursive version there is a separate variable
ls3 for each call, as we return from the recursive calls each
variable called ls3 is set to refer to a
longer list. In the iterative version, there is a single variable called
ls3 which is set to refer to a longer list each time round
the loop.
Recursion can be a useful way of developing and describing problems. It often has the advantage of being very concise. However, as we have shown with an example here, recursion should not be thought of as a "magic" way to solve a problem. Conversion of a recursive algorithm to an equivalent iterative version is possible with the employment of an extra data structure representing some of the structure given automatically behind the scene by the stack of environments in a recursive implementation. Recursion also tends to have the disadvantage, as shown in this example, of taking up more space due to the creation of new variables for new environments, whereas the iterative version would just change the value a variable refers to each time round a loop.
Let us consider a simple example, in less detail than above. Suppose we
are sorting the list [5,6,9,8,2,4,7,3] by quick sort.
This will be divided into two lists, with the first item, 5,
taken as the pivot, giving us [3,4,2] and [7,8,9,6].
The first recursive call is with the argument [3,4,2]
as the list to be sorted. This will be divided into the two lists
[2] and [4]. The list [2] is
a base case, so when it is completed giving [2], computation
returns to the environment where [3,4,2] was being sorted,
but then goes into the environment for the call where [4] is
being sorted. As [4] is a base case, it returns to the
environment where [3,4,2] is being sorted, and this method
call finishes returning [2,3,4]. Computation returns to the
top level call where [5,6,9,8,2,4,7,3] is being sorted, and
sets up a new call to sort [7,8,9,6]. This then makes two
recursive calls to sort [6] and [9,8].
So computation of the whole problem cannot be analysed in terms of execution
of a sequence of the code in each call before the recursive call going down to
the base case, then a sequence of the code in each call returning from the
base case.
This can be illustrated diagrammatically by:
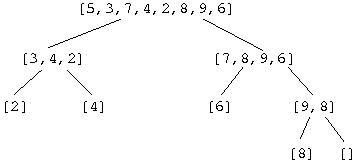
which shows how the original list is split into two with the arrows representing the recursive calls. Given the code
public static LispList<Integer> sort(LispList<Integer> ls)
{
if(ls.isEmpty())
return LispList.empty();
Integer pivot = ls.head();
ls = ls.tail();
LispList<Integer> smaller = LispList.empty();
LispList greater = LispList.empty();
for(; !ls.isEmpty(); ls=ls.tail())
{
Integer h = ls.head();
if(h.compareTo(pivot)<0)
smaller = smaller.cons(h);
else
greater = greater.cons(h);
}
smaller = sort(smaller);
greater = sort(greater);
greater = greater.cons(pivot);
return append(smaller,greater);
}
we saw previously, the following represents the situation in terms of
environments when the sort with the argument [6]
has been called and is about to return:
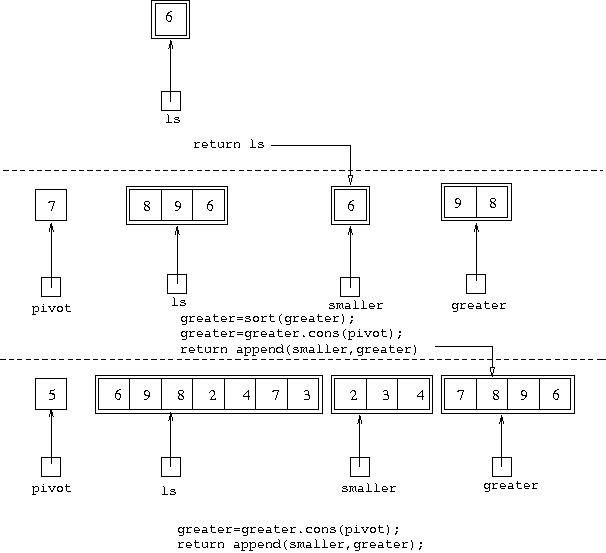
In the environment where [5,6,9,8,2,4,7,3] is being
sorted (bottom of the diagram), execution of ls=ls.tail()
has caused ls to refer to [6,9,8,2,4,7,3],
completed execution of smaller=sort(smaller) has
caused smaller to refer to [2,3,4],
while execution of greater=sort(greater) is still
underway, so greater still refers to [7,8,9,6].
In the environment where [7,8,9,6] is being sorted,
execution of smaller=sort(smaller) is underway where
smaller has the value [6]. When this has been
completed, the remaining statements at this level, shown in the diagram,
will be executed. In the environment where [6] is being
sorted, it has been found that this is a base case, so ls
is being returned as the result of the call.
public static <T> boolean oddLength(LispList<T> ls)
// Returns true if ls is of odd length, false otherwise
{
if(ls.isEmpty())
return false;
else if(ls.tail().isEmpty())
return true;
else
return evenLength(ls.tail());
}
public static <T> boolean evenLength(LispList<T> ls)
// Returns true if ls is of even length, false otherwise
{
if(ls.isEmpty())
return true;
else if(ls.tail().isEmpty())
return false;
else
return oddLength(ls.tail());
}
This method, and support code to test it can be found in
UseLispLists10.java.
reverse(ls1,ls2) returns
the result of reversing ls1 and joining it to
ls2, so for example if ls1 is
[1,2,3] and ls2 is [4,5,6]
the result will be [3,2,1,4,5,6]:
public static <T> LispList<T> reverse(LispList<T> ls1, LispList<T> ls2)
{
if(ls1.isEmpty())
return ls2;
else
return reverse(ls1.tail(),ls2.cons(ls1.head()));
}
As there is nothing to execute after recursion has finished, the
result returned from the base case is the result of the whole method
call. There is no need to save the old environments as they are never
used, and instead of creating new environments for recursive calls we
could just re-use the variables from the old environment. The above
could be re-written as:
public static <T> LispList<T> reverse(LispList<T> ls1, LispList<T> ls2)
{
while(!ls1.isEmpty())
{
ls2=ls2.cons(ls1.head());
ls1=ls1.tail();
}
return ls2;
}
In general, if a method takes the tail recursive form
public static R meth(T1 p1,T2 p2,...,Tn pn)
{
if(test)
{
code1
return r;
}
else
{
code2
return meth(a1,a2,...,an);
}
}
where the parts in italics could be replaced by any appropriate
code, the method could be converted to the iterative form:
public static R meth(T1 p1,T2 p2,...,Tn pn)
{
while(!test)
{
code2
p1 = a1;
p2 = a2;
...
pn = an;
}
code1
return r;
}
with the slight complication that the ordering of the assignments
pi = ai must be such that ai
does not contain any references to a pk that has already been
reassigned. That is why in the conversion of reverse the
assignment to ls2 was done first so that in
ls2.cons(ls1.head()), the variable ls1 refers
to the value before the assignment ls1 = ls1.tail().
Note that in a similar way, iterative methods can always be converted to tail recursive methods. The functional programming languages do not have the concept of variables whose values can be reassigned, so it is necessary to use tail recursion in them. However, in a language like Java if you find you can express a method using tail recursion it pays to convert it to iteration as that means the extra effort involved in creating new environemnts for the recursive calls is eliminated.
Last modified: 7 February 2006