head gives the first element,
tail gives a new Lisp list consisting of everything
except the head element, and cons(n) gives a new Lisp
list where the argument n is the head of the new list, and the
tail of the new list is the list the cons method was called on.
There is also the operation isEmpty which returns a boolean
saying whether the list it is called on is empty or not, and the operation
empty which returns a new list. There are no operations which
change the Lisp list they are called on, only operations which return new
Lisp lists. As a result, Lisp lists are a constructive type.
class LispList<E>
{
private E[] array;
private LispList(E[] a)
{
array = a;
}
public boolean isEmpty()
{
return array.length==0;
}
public E head()
{
return array[0];
}
public LispList<E> tail()
{
E[] a = (E[]) new Object[array.length-1];
for(int i=1; i<array.length; i++)
a[i-1]=array[i];
return new LispList<E>(a);
}
public LispList<E> cons(E obj)
{
E[] a = (E[]) new Object[array.length+1];
a[0]=obj;
for(int i=0; i<array.length; i++)
a[i+1]=array[i];
return new LispList<E>(a);
}
public static <T> LispList<T> empty()
{
return new LispList<T>((T[]) new Object[0]);
}
public String toString()
{
String str = "[";
if(array.length>0)
{
str+=array[0];
for(int i=1; i<array.length; i++)
str+=","+array[i];
}
return str+"]";
}
}
The class LispList has type parameter E.
This is indicated by following the class name with <E> in
the class header. It enables us to create Lisp lists with any base type.
Note there is no public constructor for LispList, but there is
a constructor declared as private. This is it:
private LispList(E[] a)
{
array = a;
}
The result is to create a new LispList object whose
array variable refers to the array passed to the constructor.
As this constructor is declared as private, it can only
be used by the methods in the class LispList. You might wonder
how LispList objects could be created at all without a public
constructor. You can create a new LispList list object by calling
the methods tail and cons on an existing
LispList object, but to start off you can create a
LispList object by the static method empty.
This is its code:
public static <T> LispList<T> empty()
{
return new LispList<T>((T[]) new Object[0]);
}
It's a parameterised static method with T as its parameter.
The technique we saw previously
when we used arrays to implement ArrayList is used to create
an array whose base type is given by the type parameter T.
As we noted then, this technique results in a warning being issued when the
code is compiled, but you can ignore that. The array created is of length
0 and of base
type Object, and the (T[]) causes it to be viewed
as of base type T. The static method calls the private constructor
with this as its argument. So an empty list is represented by an object
with an array of length 0 inside it. The call LispList.<Thing>empty()
will create a new object of type LispList<Thing>, representing
an empty list. Of course, Thing could be replaced by any type.
You may find the idea of an empty list or an array of length 0,
which nevertheless has to be considered as a list or array containing objects
of a particular type even though there are none of them, to be rather odd.
However, it is a necessary starting point here.
The method head simply returns a reference to the first item
in the array of the object it is called on. The methods tail and
cons work by creating a new array representing the new list,
and then using the private constructor to put that array inside a new
LispList object. In the case of tail, the new
array is of length one less than the original array and the items from the original
array (less its first item) are copied in order into the new array. In the case of
cons the new array is of length one greater than the original
array, the argument to the method is put in its first component, and the
items from the original array are copied in order into the rest of the new array.
Note the big difference between the code here and the code we saw
previously which used arrays
to implement a flexible sized array-like object. In that case, we created
a new array to represent the array changing in size, but we replaced the
existing array in the object with that new array. This resulted in
destructive operations: methods to add or delete items from the
collection caused the object itself to change. Here with Lisp lists, we create
a new array to represent adding or deleting the first element in the
cons and tail operations, but the new array
is put inside a new object using the constructor, and a reference to the
new object is returned. So the object the method was called on is not itself
changed.
In addition to the methods required for Lisp lists, we also add
code for the method toString so that if a LispList
object is printed it will be in its standard textual form, that is with enclosing
square brackets and elements separated by commas.
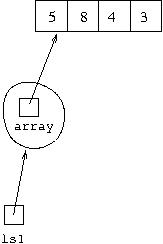
Suppose we have variables ls1, ls2 and
ls3 of type LispList<Integer>. Suppose
ls1 is set to refer to the object representing list
[5,8,4,3]. How this is represented can be shown diagrammatically as:
If we were then to execute
ls2 = ls1.cons(7); ls3 = ls1.tail();the result can be shown diagrammatically as:
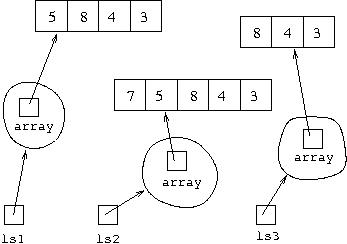
The three arrays here cannot be changed in any way because they can only
be accessed by the code inside the class LispList, and this
code does not make any changes to the arrays, it only creates new arrays.
Calling cons and tail on the object referred
to by ls1 does not cause that object to be changed, it causes
new objects to be created.
You can find the code here in the directory
~mmh/DCS128/code/linkedlists, in the file
LispListA.java.
Note it is given the name LispListA because the
alternative implementation discussed below is given the name
LispList.
class Cell <T>
{
T first;
Cell rest;
Cell(T h, Cell<T> t)
{
first=h;
rest=t;
}
}
It is a generic class, with type variable T.
An object of type Cell<T> has inside it two variables,
first of type T and rest of type
Cell<T>. It has a constructor which takes arguments
of these types and sets the variables to them, it has no other methods.
This is the simplest possible example of a recursive class,
it has inside it a reference to an object of its own type. An object of type
Cell<Integer> might have its first variable
set to 5 and its rest variable set to refer to an object
of type Cell<Integer> whose first variable
holds 8 and whose rest variable is set to refer to an object
of type Cell<Integer> whose first variable holds
4 and whose rest variable refers to an object of type
Cell<Integer> whose first variable holds
3 and whose rest variable is ... . It might
seem this would have to go on forever, but remember a variable of an object
type can be set to null. So replace the ... by "set to null"
and we have ended our description of the structure. If the original
object is referred to by a variable of type Cell<Integer>
called obj this can be shown diagrammatically as:
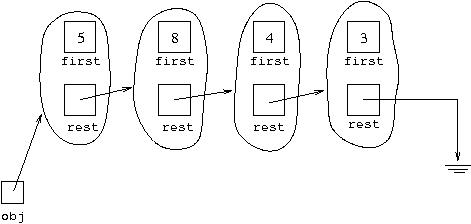
The symbol for an object variable set to
null is like that
used for "earth" in electrical circuit diagrams.
A simpler representation is:
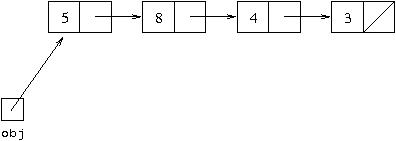
Here, a variable set to null is shown by a diagonal line through
the box that represents it. An object is represented by the two boxes
representing its variables, first and rest, joined
together. Note that an arrow representing an object reference leaves from
one of those boxes representing a variable, but points to a whole object
represented by conjoined boxes, not to any individual box. We refer to this
sort of structure as a "linked list" since it consists of cells linked
together in a list. The linked list structure may be used as a data structure to
represent the abstract data type Lisp list. The particular configuration shown above
could be used as an alternative representation of the Lisp list of integers we write
textually as [5,8,4,3].
As we did with our array representation of Lisp lists, a linked list data
structure needs to be held inside an object which represents a Lisp list.
So the complete structure for the Lisp list [5,8,3,4] is that
shown diagrammatically as:
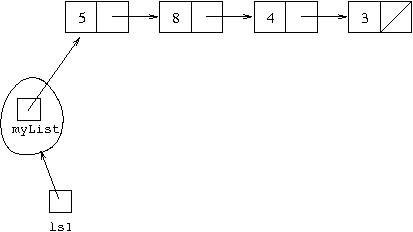
where the variable inside the LispList object called
myList refers to the actual linked list, just as in our
array representation there was a variable called array inside a
LispList object which referred to the actual array.
If we are writing a version of LispList using this
representation, the public methods must have exactly the same headings
as the public methods when we used arrays to represent lists. It is important
that this is so, because the way other classes use LispList objects
should not depend on what we choose to put inside them to make them work.
When we represented Lisp lists by arrays, the class declared a private variable
holding an array of base type E where E is the
type variable of the class, and then had a private constructor which
enabled us to put an array inside a new LispList object.
So now we need a private variable holding a linked list, let us call it
myList, and a private constructor which creates a new object
of type LispList with its myList variable set
to the argument of the constructor. This means our code for the class
LispList implemented using linked lists starts off as:
class LispListThe result of calling{ private Cell myList; private LispList(Cell list) { myList=list; } ...
head on a Lisp list represented in this
way is the value of the variable first in the cell that
myList refers to, which is 5 in the example
given. So this gives us code for head:
public E head()
{
return myList.first;
}
The result of calling tail on a Lisp list represented by
a linked list is a new LispList object holding all the elements
except the first one of the linked list from the LispList
object it is called on. If we have obj as
above, then if
we also have obj1 of type Cell<E>, then
if we execute obj1=obj.rest we get the result:
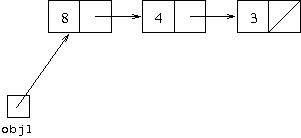
obj1=obj.rest we should show it as
obj1 to become an
alias for obj.rest which is the structure referred to
by the rest variable in the object referred to by the
obj variable. This variable is shown diagrammatically by the
right hand box of the conjoined boxes to which the arrow from the box representing
obj points. This diagram shows the code works by causing the second
cell in the linked list to be shared (and hence all the following ones to be
shared), it does not cause any actual "copying" in the sense of creating
new cells.
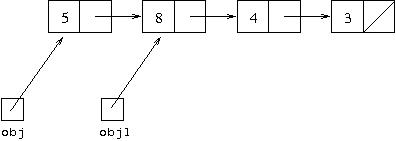
So after this, obj1 refers to a linked list whose first element is
8, whose second element is 4, whose third
element is 3 and which has no more elements. This is the
linked list representing the tail of [5,8,4,3]. But it is
important to note that obj1 is not itself the object
that represents the Lisp list [8,4,3]. As previously,
a Lisp list was represented by an object with a variable referring to
an array inside it, so now a Lisp list is represented by an object
with a variable referring to a linked list inside it. So the
following is how the Lisp list [8,4,3] is
represented with variable ls3 referring to it:
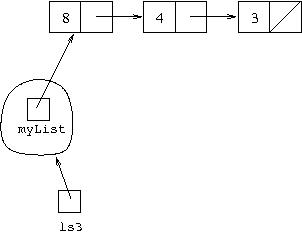
tail must get the linked list which contains
all but the first element of the original list. This is given by
myList.rest. But it must then put this inside a new object,
using the constructor for LispList, and return a reference
to that new object. This results in the code for tail being:
public LispList<E> tail()
{
return new LispList<E>(myList.rest);
}
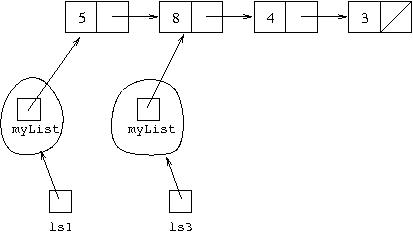
Note that the result of the call ls3=ls1.tail() can be shown
diagrammatically as:
Similar applies with the cons operation. A new linked
list which is like an existing linked list with an extra item added to
its front can be created by constructing a cell using the constructor
for the type Cell, whose first variable is
set to the extra item, and whose rest variable is set
to refer to the original linked list. Again, to complete the operation,
this new linked list must be put inside a new LispList
object, and a reference to that object is returned as the result of the
call to the cons method. This means that the code for the
method is:
public LispList<E> cons(E item)
{
return new LispList<E>(new Cell(item,myList));
}
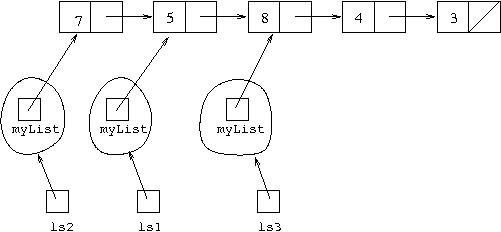
Following from our above example, if we next make the call
ls2=ls1.cons(7) the overall structure we get
is:
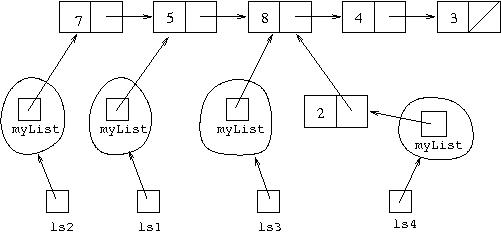
ls4 of type Cell<Integer>,
then calling ls4=ls3.cons(2) will result in the following
structure:
2 added to the front
of the linked list representing [8,4,3] does not
cause any change to the other lists which end in [8,4,3].
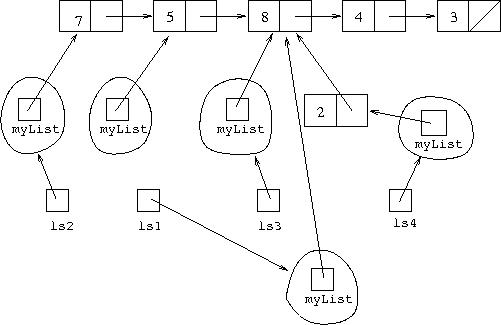
It might seem, for example, that ls1=ls1.tail() causes
a change. It does cause ls1 to stop referring to a
LinkedList<Integer> object representing
[5,8,4,3] and start referring to one representing
[8,4,3]. However, it is important to realise this is
done by constructing a new object, not by changing an existing one.
The situation after executing this can be shown diagrammatically as:
ls1 was originally referring to
has nothing referring to it. If nothing refers to its, it "disappears"
(meaning that the computer store allocated for it may be re-used).
However, it is possible that another variable could have been set to it,
for example ls5=ls1 causes ls5 to refer to what
ls1 refers to (aliasing), and it stays referring to that
even if ls1 is changed to refer to something else.
If the object that ls1 originally refers to disappears,
the cell its myList variable refers to, containing 5
does not disappear, because it is still referred to by the rest
variable of the cell containing 7.
An empty list can be represented by an object of type
LispList whose myList variable is set to
null. For example,
ls5=LispList.<Integer>empty() would result in
what could be illustrated diagrammatically as:
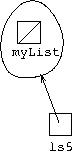
empty can be given by:
public static <T> LispList<T> empty()
{
return new LispList<T>(null);
}
So note that an empty Lisp list is not represented by null but by
an object which has a variable referring to a linked list inside it,
and that variable is set to null. This is important,
because we want to be able to call methods on an object representing an
empty Lisp list. We want to be able to call the methods cons,
isEmpty and toString on it. You cannot call any
method on null (or a variable set to null),
if a method is called on a variable and that variable is set to null
when the code executes, a NullPointerException is thrown.
Note that as we have given the code, a NullPointerException
will be thrown if the methods head or tail
are called on an object representing the empty Lisp list. This is because
head attempts to access the variable myList.first
and tail attempts to access the variable myList.rest,
but myList is set to null for an empty Lisp list.
Putting all this together, the following code gives a complete implementation of Lisp lists using linked lists:
class LispList<E>
{
private Cell<E> myList;
private LispList(Cell<E> list)
{
myList=list;
}
public boolean isEmpty()
{
return myList==null;
}
public E head()
{
return myList.first;
}
public LispList<E> tail()
{
return new LispList<E>(myList.rest);
}
public LispList<E> cons(E item)
{
return new LispList<E>(new Cell<E>(item,myList));
}
public static <T> LispList<T> empty()
{
return new LispList<T>(null);
}
public String toString()
{
if(isEmpty())
return "[]";
else
return "["+head()+restToString(tail());
}
private static <T> String restToString(LispList<T> l)
{
if(l.isEmpty())
return "]";
else
return ","+l.head()+restToString(l.tail());
}
private static class Cell <T>
{
T first;
Cell<T> rest;
Cell(T h,Cell<T> t)
{
first=h;
rest=t;
}
}
}
This code can be found in the file
LispList.java
in the directory ~mmh/DCS128/code/linkedlists.
You can see an odd thing here, the class Cell is declared
inside the class LispList (you can tell this because
the opening { isn't matched by a closing } until
the last line). A class declared inside another class is known as a
nested class. Like methods and variables declared inside classes
but outside methods, a nested class may be declared as public
or private, and it may or may not be declared as static.
Declaring a nested class as private means it may only be
used by other code in the same class. Declaring a nested class as static
means, like declaring a method as static, that it is self-contained, it
is not attached to any particular object of the class it is in.
So the class Cell is declared as static private
inside the class LispList. This means that objects of the type
Cell can only be created and accessed by the methods in the
class LispList. It cannot be referred to at all by any other
code, although when the public methods for LispList are
called, that will result in objects of class Cell being
manipulated.
The cells and pointer diagrams showing how the implementation using linked lists works only need to be considered when building the implementation. You need not be concerned about what is happening underneath when you run code using linked lists.
Computer programs for realistic applications are long and complex.
Separating the code into different portions, each of which can only
interact with other portions in particular ways defined by their
public methods, is a good way of making sense of our code and
being able to modify it and being assured that modifying one portion will
not have unexpected effects on another. For example, we might originally
have decided to use the array implementation of Lisp lists, and then
written programs using Lisp lists. When we realised the linked list
implementation would be more efficient, none of our programs which used
Lisp lists would need to be changed because they relied only on the
public methods for Lisp lists: head, tail,
cons, isEmpty and empty (and
also toString) and changing the implementation did not change
the public appearance of the way these methods worked.
Last modified: 3 March 2006