Each question was marked out of 20, for a total of a maximum of 80 marks for the paper. However, for the purpose of a final mark for the whole course, the paper will be treated as if it is marked out of 75. Given that the test counts 15% of the final marks, this means that every five marks on the test will count 1% towards the final assessment of the course.
A table giving the marks for each student, but with students given only by examination number, can be found here.
Below is some discussion on the test together with solutions.
A complete and correct answer to this question would be something like:
A pointer is set to the root item. Then repeatedly the pointer is moved to the
left branch if the item to be deleted is less than the root item of the cell
the pointer is pointing to, or to the right branch if it is greater. This
is done until one of the following conditions holds: the item to be deleted is
in the root of the left or right branch and at least one of its branches is
null, or the item to be deleted is the root item of the
cell being pointed to.
If the item to be deleted is in the root of the left or right branch, the
pointer to that branch is replaced by null if both of that
branch's branches are null, otherwise the pointer to that
branch is replaced by whichever branch of the cell it is pointing
to is not null.
If the item to be deleted is found to be in a cell with non-empty left and
right branches, then that item is replaced by the rightmost cell of the
left branch and that cell is deleted. This means that if the left branch has
no right branch, the left branch is replaced by the left branch of the
left branch. Otherwise, a second pointer is put at the root of the left branch
and moved down the right branches until it points to a cell whose right
branch points to a cell whose right branch is null.
Then the root item of the cell the original pointer points to is replaced
by the root item of the cell at the root of the right branch of the cell
the second pointer points to. Then the right branch of the cell the
second pointer points to is replaced by the left branch of the cell
the right branch points to.
As the question specifically asks for an explanation of destructive deletion, for full marks it was necessary to explain it in terms of pointer operations like this. No-one managed to get this completely correct. As in the first question of the first test, many people scored badly on this question because their answers were very vague. It is necessary in this sort of question to use language which makes it quite clear what you mean and cannot be interepreted in any other way.
However, there was nothing tricky about the question: the algorithm had been covered in detail in the lectures and the web notes, and so anyone taking this test ought to have had a fair idea it would come up and they would need to know it. The question did not require any working out or special intuition. A less detailed answer which missed the full details of pointer manipulation could still have gained about 15 marks out of the full 20.
A common mistake made was to ignore the first part, which was the search through the tree moving either to the left or right to find the location of the item to be deleted. It was essential to note this, because when we have a tree initially we have only a pointer to its root, we do not know until we have searched, where any other item is in it.
Many others, when talking about deleting an item in a cell with non-empty left and right branches did not clearly specify that it should be replaced by the rightmost item of the left branch. Some just wrote "rightmost item" (which is wrong), others wrote that it would be replaced by the item immediately below it in the tree (also wrong).
I was surprised by how many people drew trees to illustrate the problem but drew trees which were not ordered - that is they had cases where somewhere in the right branch of a tree was an item less than the root value of the tree, or somewhere in the left branch of a tree was an item greater than its root value. Marks are deducted for making an elementary mistake like this.
class Cell
{
int first;
Cell next;
Cell(int f, Cell n)
{
first=f;
next=n;
}
}
The first part of this question asking for the list to be changed
destructively was reasonable well done. Here is what an answer should
look like:
static void change(Cell list,int m, int n)
{
for(Cell ptr=list; ptr!=null; ptr=ptr.next)
if(ptr.first==m)
ptr.first=n;
}
There were still a few people, however, who had difficulty with the very
idea of a method which takes arguments and so did not even get the header
correct. A common mistake, despite it being pointed out when many people
made a similar mistake in the first test, was to confuse the problem with
the example given to illustrate it. The example showed a case where the
two integers were 5 and 8.
This did not mean, however, that you were meant to write code
that changed every 5 in a linked list of integers to 8. The numbers
5 and 8 should not have featured in
any answer to this question. The code should take any two
numbers, given as parameters to the method, m and
n in the example above, and change all occurrences of the
first to the second. The example given was just to illustrate one possible
run of the code.
Quite a few people used the type List rather than
Cell. This was wrong because the question made no mention
of any class called List, linked lists are made up of cells,
with the start of a linked list being the pointer to its first cell, so
they are of type Cell.
A common mistake was to write the loop header as:
for(Cell ptr=list; ptr.next!=null; ptr=ptr.next)This would mean that if the last cell contained the number which is meant to be changed it wouldn't get changed. Remember that a for-loop has the form
for(init;test;update) body.
This is equivalent to:
init;
while(test)
{
body;
update;
}
except that if init declares any new variables they
would be accessible after the while loop but not after the
for loop. So if the update is ptr=ptr.next and
the test is ptr.next!=null, you will see that as soon as
the update moves ptr to point to the last cell, the loop
exits and the body is never executed with ptr equal to the
last cell. There are times when you want the test to be or include
ptr.next!=null, for example when you want ptr to end
pointing to the last cell so you can add something to the end of the list.
However, when you are simply altering the value in each cell, you want to
carry on until all cells have been altered and ptr has gone right
through and has value null.
A rather strange mistake which was made by several people was to write code that would change all occurrences of the first integer to the second and all occurrences of the second integer to the first. So they wrote a body to the loop something like:
if(ptr.first==m)
ptr.first=n;
else if(ptr.first==n)
ptr.first=m;
If this is what the question wanted, it would have said that. However, it
said only change all occurrences of the first integer to the second,
it said nothing about changing all occurrences of the second integer to
the first. If you were a computer programmer and you were asked to write some
code that changed all X's to Y's in some circumstance, imagine the havoc you
could cause if without being told you wrote the code so that it also
changed all Y's to X's. Suppose the code was running over student records
and X was "grade B" and Y was "grade A", for example. The lesson here is that
when you are asked to write code to do something, do not take it on yourself
to make that code also do something else that might not have been wanted.
The part of this question asking for code for a constructive version of
the operation was very badly answered. It has been made clear to you that
constructive operations on linked structures are best handled through
recursion. Here is a suitable answer for the second part of question 2 using
recursion:
static Cell change(Cell list,int m, int n)
{
if(list==null)
return null;
else
{
Cell rest = change(list.next,m,n);
if(list.first==m)
return new Cell(n,rest);
else
return new Cell(list.first,rest);
}
}
In other words, if the list is empty, return empty. Otherwise, first
create a new list consisting of all m's changed to
n's in all of the original list apart from its first element,
then put n on the front if m was on the front of the
original list, otherwise put what was on the front of the original list
on the front of the new list.
I think this is a very clear and simple way of thinking about the problem.
Over half the class, however, tried to tackle this in an iterative way, and
just one of those who did so managed to do it correctly. There are
two ways it could be done iteratively. Here is a correct answer using the
"pointer at back" approach:
static Cell change(Cell list,int m, int n)
{
if(list==null)
return null;
else
{
Cell list1;
if(list.first==m)
list1 = new Cell(n,null);
else
list1 = new Cell(list.first,null);
for(ptr=list,ptr1=list1; ptr.next!=null; ptr=ptr.next,ptr1=ptr1.next)
if(ptr.next.first==m)
ptr1.next = new Cell(n,null);
else
ptr1.next = new Cell(ptr.next.first,null);
return list1;
}
}
The important thing is that we need to make sure that new cells that are
created are attached to the structure that starts at list1,
and this is done by altering the field of the last cell of the structure
headed by list1 each time round the loop. Many people gave
answers which looked like they might have been trying to achieve what
is done above, but created new cells that weren't linked to anything.
Another way of solving this problem iteratively is to use the "stack and
reverse" technique. Hardly anyone chose to use this technique, but the one
person who gave a correct answer that didn't use recursion did it in this
way. Here is a solution using "stack and reverse":
static Cell change(Cell list,int m, int n)
{
Cell stack=null;
for(;list!=null;list=list.next)
if(list.first==m)
stack = new Cell(n,stack);
else
stack = new Cell(list.first,stack);
for(;stack!=null;stack=stack.next)
list = new Cell(stack.first,list);
return list;
}
The important thing to note in this question is that a correct answer must create a new cell for every cell in the solution. Any answer that did not create new cells could not possibly work. For example, the following was quite often suggested as the body of the method:
Cell list2=list;
for(Cell ptr=list2; ptr!=null; ptr=ptr.next)
if(ptr.first==m)
ptr.first=n;
return list2;
Setting a new variable list2 to list makes no
difference, it still points to exactly the same cell that list
points to, it doesn't create a new list. So setting ptr to that
cell means ptr is set to point to the same cell as in the
original list, and if that cell is changed it is a destructive change.
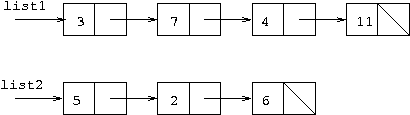
Cell as in question 2, and three
variables of class Cell called list1,
list2 and ptr. For each part of the question
assume the initial situation is restarted to be as in the cells and pointers
diagram below. Sketch what would be the situation after the execution
of the code fragments given.
for(ptr=list1; ptr.next!=null; ptr=ptr.next) {}
ptr.next=list2.next;
Answer:
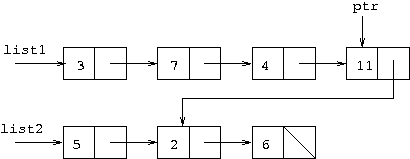
The first line here is the standard loop for moving a pointer to the
last cell of a linked list. The {} at the end of it
indicate that it is a "loop without a body", so the next line is not
part of the loop. The second line causes the field represented by
ptr.next to stop having the value null and
start having the same value as the field list2.next, so
it is made to point to the same cell that list2.next points to.
Note that pointers come from fields, indicated by parts of cells, and this should be shown clarly by the pointer coming from the middle of the part of the cell representing the pointer field. But pointers point to whole cells, not to parts of cells, so the arrow at the end of the pointer should be next to the outside of the cell it points to, and it does not matter which part of that cell it points to.
Some people gave answers to this in which the linked list starting
at list1 had separate cells containing 2 and
6 added at the end. This is wrong. In cells and pointers
diagrams it is important to show when cells are shared as this
represents a different situation form the case when the lists have
separate cells but containing the same numbers.
A few people showed the cell containing 11 as having a
diagonal line through its next field and a pointer coming from the
cell. This is wrong, since the diagonal line indicates a field set to
null and it is obviously impossible for a field to be both
null and point to a cell.
Some people gave cells and pointers diagrams but did not clearly indicate
what list1 referred to and what list2 referred
to after the execution of the code. In the answer given above, it is also
shown what ptr refers to after the execution of the code,
since it does not end being set to null.
Other errors seemed to be caused by people not knowing what the
assignment ptr.next=list2.next does.
for(ptr=list1; ptr!=null; ptr=ptr.next)
ptr.first = ptr.first*3;
list2.first=list2.first*2;
Answer:
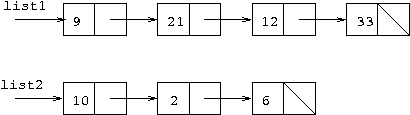
This part was the best done of all the parts of this question. Perhaps
the most common error was not to understand correctly what was in the
loop and what wasn't. If a for header is not followed by
a {, then only the next statement is in the loop and the
statement after that is not in the loop. An assignment is a statement.
So ptr.first = ptr.first*3 is in the loop while
list2.first=list2.first*2 is not. This is also indicated,
as is convention, by the code which is inside the loop being indented.
So it can be seen that this is the standard pattern of moving a pointer
down a list changing each of the cells (in this case, multiplying
their first field by 3). Following this is a single
statememnt in which the first field of list2
is multiplied by 2. This last statement does not affect any other cells
in the list headed by list2.
for(ptr=list2; ptr!=null; ptr=ptr.next) {
ptr.first = ptr.first*3;
list1.first = list1.first*2;
}
Answer:
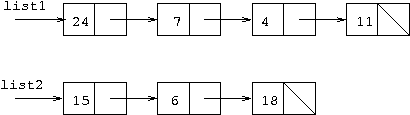
Again, there were problems with people who still have not understood how
compound statements work. In this case, the opening { occurring
after the for heading indicates that everything that follows is
in the for loop up to the closing }. Contrast this with
the previous question where the lack of a { means only the
first statement following the for loop heading is in the loop.
So in this case we have
a pointer moving down the linked list which starts with the reference in
variable list2 (note carefully, as one or two people didn't
that in this case it was list2 whereas in the previous
part it was list1). The first statement in the loop body means
that each time round the loop, the
first field of the cell that ptr is pointing
to gets multiplied by 3. So when the code is finished, all the cells in
the list referred to by list2 have their integer value
multiplied by 3. The second statement in the for loop body multiplies the
first field of the cell referred to by list1 by
2. However, the variable list1 remains referring to the same
cell throughout the execution of the loop, so the first
field of this cell is multiplied by 2 three times, making it 24
eventually, as ptr
is moved three times before it becomes null.
list2.next = list1.next; for(ptr=list1; ptr.next!=null; ptr=ptr.next) ptr.first = ptr.first+10;
Answer:
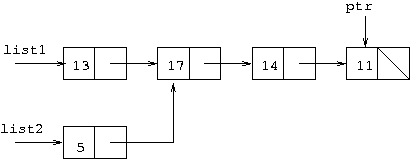
There were a couple of tricky issues in this question. The first statement
causes list2.next to refer to the same cell as
list1.next. This is indicated diagrammatically by
list1 and list2 pointing to separate cells each
of which has a pointer field with an arrow pointing to the same cell.
It is important to note that we have actual cell sharing here, because
when ptr is set to move down the list starting with
list1 in the loop that follows, adding 10 to the
first fields, the cell which contains 7 has 10 added to its
first field and this change is shared with the list
starting at list2, as is the change to the next cell,
as these cells are shared in the lists. Some people seemed to think for
some reason that the list starting at list1 would be
affected by the changes in the loop, but not the list starting at
list2.
The other tricky issue in this part of the question was that the loop test
was ptr.next!=null and not ptr!=null. This
means the loop is exited when ptr points to the last cell in
the list but before 10 is added to the first field of that
cell. A lot of people assumed that the value in this cell would be
changed from 11 to 21.
A complete and correct answer to this part of the question would be something like:
A nested class is a class that is defined within the body of another class. It is used where the nested class will be referred to only within the enclosing class, for example to construct a data structure which the enclosing class uses to implement its public methods.
This part was mostly answered quite well, although some answers were a little too brief. For example, just writing that a nested class is a "class within a class" isn't quite clear enough, it was necessary to be a bit more precise over what this meant by noting that it is a class defined inside another class.
StringTokenizer works.
A complete and correct answer to this part of the question would be something like:
A string tokenizer is created with a string as its argument and breaks the string up into separate words. By default space characters are treated as separators between words, though it is possible to specify other characters to be treated as separators. A string tokenizer has a method nextToken(), and each time this method is called on it the next word from the break up of the original string is returned. There is also a method hasMoreTokens() which returns true when called before all the words have been returned, and false after they have all been returned.
Many of the answers to this were too vague. They did not say how the string was broken up, and how the separate words were returned. It was essential for full marks for this part of the question to make clear you understood that the separate words were returned through repeated calls to a method which returned a new word each time it was called. Some people in answering this question actually wrote, wrongly, that the separate parts were put in an array or some other structure by the string tokenizer.
A lot of people wrote answers to this question which used the word "read".
It was not altogether clear what they meant by this because a string tokenizer
does not read anything, in the strict sense of the word which means to take
in text information from an external source such as a file or display. You
should not use the word "read" to mean "go through some collection
of information" or "take as an argument". When a method takes something as
an argument it means an internal transfer of references to some structure
within the execution of a program, and this should not be referred to
as "reading", and a method returning a result should not be referred
to as "writing" it. While a string tokenizer often is used to break up
text read from a file or entered by the user of a program, it does not
actually do the reading itself, it simply takes as an argument a string
value which has already been read through the use of some other method,
such as the method readLine() called on an object of type
BufferedReader.
head, tail and
cons do when called on an object of abstract data type List.
A complete and correct answer to this part of the question would be something like:
A List is a collection of data in which the order of the data is singificant. The method head returns the first item in the collection. The method tail returns a new collection which consists of all the items from the collection it was called on in the same order but missing the first item. The method cons takes an argument and returns a new collection which contains all the items from the collection it was called on in the same order, with the argument item added to the front.
This part of the question was not very well answered, despite the fact that
a lab exercise using the abstract data type List had been given
the day before, so everyone should have done this and learnt about the ADT List from it.
Quite a few people gave completely wrong answers to this, and many who
were otherwise on the right lines supposed that tail gave the
last item of a list. Clearly this suggests that people have not done
the lab work. You need to recall that labwork is set because the material in
this course is best learnt by practising with it. If you don't do the labwork,
you will not gain familiarity with important principles.
Some people answered this question as if it were one on linked lists, making
reference to "cells" and the "first" and "next"
field. This is to ignore one of the most important issues in this course:
the need to draw a clear distinction between an abstract data type and
the data structure that might implement it. An abstract data type list is
viewed only in terms of the operations possible on it, and so
should be discussed only in terms of how those operations interact.
An abstract data type list could be represented by a linked list as
its data structure referred to within the code that implements it, but it
needn't be. An alternative representation would be to use an array and
count data structure, which indicates that it is clearly wrong to talk
about it in terms of cells and fields, since these are not a necessary
component of a list.
Another common mistake was not to make quite clear that you understood the
methods on an ADT List to be constructive. It would be wrong, for example, to
say that the method cons "adds an element to a list" because
that suggests it changes the list. You needed to make quite clear that you
understood it creates a new list. You also needed to be clear that you
understood cons to create a new list which was like the
original list with the new element added to the front. Not stating
this is another example of being too vague in definition questions, since
your answer could then equally apply to other abstract data types such as
queues or sets or sequences. It was not enough, either, simply to describe
the operations tail and cons as if they were
destructive and add something like "done constructively" to the end. It
was important to show you really understood the concept of an operation
being constructive by describing it in a way that makes clear it returns
a new object and does not change the one it was called on.
A complete and correct answer to this part of the question would be something like:
To traverse a tree is to go through each of the items stored in the tree doing some operation on each of them. A pre-order traversal of a tree does the operation on the root item of the tree, then does the traversal recursively to its branches. A post-order traversal of a tree does the traversal recursively to its branches, and finally does the operation to its own root item. An in-order traversal of a binary tree does the traversal recursively to one of its branches, does the operation to its root item, then does the traversal recursively to the other branch.
Many people in answering this part of the question just put something like
Root, left, right
Left, right, root
Left, root, right
which does not clearly explain what is meant by the terms. It was necessary to explain that a single operation is applied to the root and the traversals of the branches are recursive.
As with question 1, another problem was to illustrate it with an example, but to use an example of a tree so small that it did not clearly indicate an understanding. For example, with a tree of just three elements, one in the left branch, one in the right, pre-order traversal is the same as breadth-first would be, so it is not enough to indicate that you understand the difference. Nor is it enough to give just an example without explaining the general rules for getting the order of your example.
A few people thought "pre-order" and "post-order" referred to the state of the tree before and after some sort of ordering operation on it. Again, these terms were clearly explained in the notes, so to make such a mistake suggests you have not taken the basic step in preparing for the test of at least reading the relevant notes.